I have been using Geany for years to edit code. Mostly for
JavaScript and PHP and lately for Lua. It gives great productivity
as you can search code with a shortcut. It searches for function
definitions, but you can also search for any text. And you can
click results to quickly navigate there.
The only problem is that all files need to be opened to get
included in the search. So I use the Project feature to organize
open files and simply open all my Lua files. For the game I'm
currently making, that's around 20 files. It works fine on Mac,
but on Linux the default GTK theme makes the file tabs very
big and 20 cannot fit on the screen. So I have to navigate
between Files/Documents and Symbols tab all the time instead
of having it all on one screen.
I have googled a lot to find the way to reduce the size of
tabs because Geany itself doesn't have an option. Even if you
reduce the font size, there's just too much padding with blank
space.
Today I discovered GTK Inspector. A tool that allows you to
run any GTK application and inspect it's elements. Just run
Geany like this:
GTK_DEBUG=interactive geany
Then press Ctrl+Shift+D and Alt+tab into inspector.
After some fiddling, I managed to find the notebook tab
elements that control the font and spacing. I was still a mystery
how to write proper CSS as the one shown in Gtk Inspector seemed
strange and had a lot of text that you cannot copy/paste. Then
I noticed it shows the .css file from the theme. In my case, it
was gtk-contained-dark.css. And in that file I finally found
the CSS responsible for layout. I typed the following custom CSS
into Gtk Inspector:
The next step was to make this permanent. I added the same
CSS line into ~/.config/gtk-3.0/gtk.css file in my home directory
and finally I can get full productivity with Geany.
I decided to toy around with Apache on macOS High Sierra and
wanted to make sure it only listens to localhost connections.
To check open ports, you can use netstat like this:
Ok, Apache is fine, but this got me curious. PID 60 is
XBox360 controller driver and PID 323 is rapportd. Why either
of those needs to listen for network connections is beyond me.
PID 161 is FirebirdSQL DBMS, so I disabled it as I don't
really need it currently, by editing the file:
/Library/LaunchDaemons/org.firebird.gds.plist
and setting the keyname Disabled to true.
I'm still looking for a way to disable rapportd and XBox360 daemon.
Installing software like Firebird DBMS adds users to your
macOS system. In this particular case it added the user firebird, but
I also wanted to toy around with the Firebird embedded variant, which
has some magic for SYSDBA user. So I also added user named SYSDBA manually.
The problem is that my login screen now shows a bunch of accounts
that cannot really be used. It's incredible that macOS has no GUI
to simply exclude some accounts from the login screen. I guess it can
pose a support problem down the line when people forget they hid
some account and have no idea how to get it back... oh well.
Anyway, there's a way to at least bundle all of those accounts you
don't need into a Other category. It's done with a command like this one:
The only problem is that this setting gets ignored after restart
if you use full-disk encryption. Apparently the setting is stored in
the encrypted part of the disk, and Mac shows the login screen before
you decrypt it. Not really sure where it reads the list of users
from in that case?
CheapSSLs website sells cheapest mainstream SSL certificates currently.
Apparently they are part of NameCheap group and also run ssls.com website.
Prices are really low, and running SSL is not really that expensive anymore.
In my setup, I'm mostly using stunnel in front of HAProxy, which then
does load-balancing to a bunch of nginx, Apache and node.js servers.
Configuring each of those for SSL would be PITA, so I'm simply using
stunnel. The only drawback was getting IP addresses of connected web clients.
This can be solved with proxy protocol using HAProxy 1.5, but I also use
websockets and json-polling and xhr-polling
with node.js and socket.io I cannot use the proxy protocol. So I patched
stunnel 5.0 with 4.x patch you can find on the net, to give me
additional HTTP headers.
When you apply for SSL cert at cheapssls, they ask for the type of
web server and even though there are 20+ options, stunnel is not one
of them. So I picked "other". I got three files:
mydomain.csr
AddTrustExternalCARoot.crt
PositiveSSLCA2.crt
BTW, to create the certificate request, I used the same
procedure as with GoDaddy.
I tried to set it up using intuition and previous experience with
GoDaddy, but it just would not work. I would get this error:
[!] SSL_CTX_use_PrivateKey_file: B080074: error:0B080074:x509 certificate routines:X509_check_private_key:key values mismatch
[!] Service [domain]: Failed to initialize SSL context
So I tried to use the CAfile setting, copy/paste certificates again,
and stunnel just would not start. If I removed intermediate certificates
it would work, but then it would not support all the browsers out there.
Finally, after a lot of trial and error and trying out various howtos
on the net, I got it working. Here's how to do it. First, create a file
containing your certificate, intermediate certificate and root certificate,
in that exact order. This is important, because it would not work
otherwise:
In mid of July I posted a link to my blog post about Yahoo! Mail
(see previous post) to Hacker News. The post was quickly
picked up, and reached the front page:
HN effect lasted for two days. As soon as the story left the front page,
traffic dropped. My blog gets 30-40 visits per day usually.
In those two days, it got about 14000:
The only feedback and social sharing mechanism I use on this blog is
Twitter. As a side effect, I also got about 10 new Twitter followers
in those few days.
Conclusion: HN posting could be useful to get some attention, but
keep in mind that it would only last for a day or two. As you may
notice, I don't have any ads on my blog, the real purpose of my blog
posts is just sharing my thoughts with the community.
Using GMail with intermittent connection on my Android device has
always been slow, but I simply thought that's the way things should be.
Some two months ago, I needed to read my, over a decade old @yahoo.com
mail, and I installed Yahoo! Mail app on my Android. What a pleasant
surprise that was. It is FAST. Much faster than Gmail. I wrote YMail off
on the desktop, but on mobile it was clearly better and I enjoy reading
and sending mail on it.
Today, I logged into Yahoo! Mail on my desktop machine, and I was
in for another surprise. They fixed the "paging" issue, and made it
run even faster than before. Replies are much easier than using GMail's,
recently introduced narrow space. Not to mention that PageUp and PageDown
keys work properly:
GMail has caused so much pain to me lately. A couple
of e-mails sent accidentally because I pressed PageDown and hit space.
Instead of moving the cursor to bottom and adding space, GMail moved the
focus from text box to the Send button and pressing Space key on it
made it send the message. Also, it's impossible to select text with Shift+PageDown
in GMail. Unless you have 30" monitor which is presumably why all the
Google engineers are completely unaware of the issue. GMail reply is
UX nightmare on laptop with standard resolution like 1280x800 or 1366x768.
Another issue I had with Yahoo mail in the past is also gone. Earlier
when you had a lot of messages to select (say, like 100+) you would
either have to scroll page-by-page in old, classic view or you could
switch to modern one which would load everything. With 1000+ messages
in my, 14-year old, inbox this posed a problem. Now they fixed that. I
loads initial set of messages and keeps loading more as you scroll down.
When I reach those 100-something messages I need to select, I can easily
select them all in one go. Not that I think about it, GMail does not
have this feature, so that's one more reason to use YMail.
Let's face it, with free GMail for domains removed from market, and
latest improvements in Yahoo Mail, Yahoo seems to be a clear leader now.
It's faster, has more features, and it's much easier to reply to messages.
I hope GMail team wakes up soon.
Gods of Sparta is a card
strategy game I've been working on in the past 3 months. It's a
card combat game, but without all the trading, collecting, booster
pack nonsense that makes you waste money on cards that you'll never
use. The game is oriented on strategy, both players have equal chance
to win, and it's played in real-time (although it's turn based, players
have about 30 seconds to play their move). It's really easy to learn,
but hard to master.
5 designers were hired to create graphics
for the units, while I did programming and all the rest. Visit the Gods of Sparta website
to try it out
Creating a checkbox is rather simple, but here's some code that
you can use in your project without having to invent it yourself.
For checkbox or toggle button we need two images representing the
states: checked/unchecked, on/off, yes/no, etc. You need to prepare
those two images and load them into a createjs.Bitmap. In the game I'm
creating, I used these two images:
Of course, you can place both images in a single file and then
use sourceRect property to create two bitmaps. The code would go like
this:
var imageUnchecked = new createjs.Bitmap('checkboxen.jpg');
imageUnchecked.sourceRect = new createjs.Rectangle(0, 0, 34, 29);
var imageChecked = new createjs.Bitmap('checkboxen.jpg');
imageChecked.sourceRect = new createjs.Rectangle(34, 0, 34, 29);
Now that we have both images, lets create a checkbox. All you need
is a simple function call:
var xPos = 100;
var yPos = 100;
var initialState = true; // checked initially
var btn = new toggleButton(xPos, yPos, imageChecked, imageUnchecked,
initialState, function(isChecked) {
if (isChecked)
// do something
else
// do something else
});
To read the state later, outside of click handler, use the following code:
if (btn.checked)
{
// ...
}
Of course, for this to work, you need toggleButton function. Here it is:
Searching the Google for grayscale easeljs leads to some
obscure StackOverflow Q&A from 2011. which has a working example.
However, it uses a generic filter matrix so you would need to know how
grayscale effect actually works on pixel level to understand what it
does.
It's much easier to use Easel's built-in functions. However, those
are not easy to discover using a search engine. You have to dig into
docs. Here's an easy way to do it, adapted from Easel docs.
Assuming you have a Bitmap, Container, Shape in variable myDisplayObject:
var matrix = new createjs.ColorMatrix().adjustSaturation(-100);
myDisplayObject.filters = [new createjs.ColorMatrixFilter(matrix)];
myDisplayObject.cache();
Make sure you call cache() at the end, because filters are only applied
during caching. If you wish to use different filters for different objects
in a container, you need to cache() each one separately before adding
to container.
Now, you might run this example, and get the error message createjs.ColorMatrix() is not a constructor
because createjs.ColorMatrix is undefined. The reason for this is that
current version of minified files does not include filters, so you
need to include ColorMatrixFilter.js script in your page
separately. Lanny says
it will be included in one of future versions. I'm not sure that's a good
idea though. I doubt many users use filters. I almost built the entire
game without it, and only want to include it for Medusa's petrifying
effects.
I'm developing a HTML5 game and although there are many ways to
track image loading, they mostly use XHR which does not work reliably
in different browsers. I don't care about progress bars, but I do
compose images after loading (using EaselJS cache) and need to make
sure images are loaded before caching.
The usage is really simple. In case some of the images fail to load,
or takes too long, you could have a problem that program would not
go on, and user won't see anything. To avoid this, I added a custom
timeout, after which the callback would be called regardless. The
timeout resets after each successfull download, so don't set it
too high. The example below uses 12 seconds:
// 1. create image loader
var imageLoader = new ImageLoader(12);
// 2. feed it some URLs
imageLoader.add('shadow', 'http://mycnd.com/shadow.jpg');
imageLoader.add('ball', 'http://mycnd.com/ball.png');
imageLoader.add('player', 'http://mycnd.com/player.png');
// 3. wait for load to complete and then do something with the images
imageLoader.loadAll(function() {
// do something, like for example:
var ballSprite = new createjs.Bitmap(
imageLoader.get('ball'));
});
The code uses alert() in two places. Please replace that with
whatever error handling you use.
Also, there could be a better/faster way to detect image files that are
not available (HTTP code 404 and similar), so that we don't have to
wait for timeout.
In the HTML5 game I'm making, I needed to have many identical sprites.
At first, I used the generic new Bitmap('path.png') code, but it
uses a lot of memory that way. I searched the web and finally asked at
CreateJS forums. The answer is simple and easy:
var image = new Image(); // create HTML5 image object
image.src = 'url.png'; // load image from file
// now, just repeat the following for each sprite
var sprite = new Bitmap(image);
BTW, I did search for image class in EaselJS docs, but apparently
it is not listed as it is a regular HTML5 type of object. I guess you
should still learn HTML5 basics even if you use a wrapper library.
If you have an old Quicken Home Inventory or Quicken Home Inventory
Manager installation and want to
save your inventory database, you probably have problems using this
data on a new computer system. This is because of various incompatibilities
between multiple versions of Intuit inventory programs.
However, there's a simple way out. Download a program called Attic
Manager. It's a home inventory program, just like QHIM, with one specific
feature: it is able to import databases of all Quicken Home
Inventory programs. At the time I write this, it supports the oldest IDB
files, then the newer .QHI files and also the latest MDF files which
come with most recent versions of Quicken.
Now, how does this help you, when you have a DAT file? Well, QHI.DAT
is not really a database with your items. If you have QHI.DAT file,
this means you have the oldest version of QHI, and there should be
a file called QHI.IDB around as well. Attic Manager is able to load all
items, locations, categories and other data from QHI.IDB file, so use
that one.
As far as I know, Attic Manager is the only product on the market
that is able to do this. Once you load the database into Attic Manager,
you can export it into CSV format and then load into any Inventory program
that supports loading from CSV or Excel (most of them do). Or, you can
simply use Attic Manager itself. It is simple, clean, and fast. It
works on newer versions of Windows, like Windows 7 and Windows 8 and also
on 64bit systems as well. And
knowing your data can be exported at any time sets you free from vendor
lock-in.
A few days ago, Sebastian DeRossi asked
me on Twitter how to improve Easel.js
docs. As this is too large for Twitter's 140 characters, here's
a short blog post of some issues I found:
1. I was looking for a way to Flip an image and docs don't mention
that you can use negative values to scaleX and scaleY. I was really
planning to work around this by creating all the required mirror
images using ImageMagic and load 2 sets of sprites, when I accidentally
found the example using negative values on some blog while searching
for something completely different.
2. Say you are a complete beginner like me, and you wish to add a
mouse click event handler to Bitmap. You would go into docs,
click Bitmap, go
to list of events, where it says Click and there
are links to DisplayObject and MouseEvent there, but none of those
lead to example how to actually use it. Failing this, I first
found onClick only to find out that it is
deprecated and I should use addEventListener(), without any example
how to use it. BTW, I did manage to get onClick to work, but I did
not want to use a deprecated function. In the end, I asked on StackOverflow
and got a real example how to use addEventListener for mouse events.
3. The thing I'm still confused about, is what is the standard application
structure. I.e. how to do the main game loop? In docs, the
Getting Started
section ends with this:
//Update stage will render next frame
createjs.Ticker.addEventListener("tick", handleTick);
function handleTick() {
//Circle will move 10 units to the right.
circle.x += 10;
//Will cause the circle to wrap back
if (circle.x > stage.canvas.width) { circle.x = 0; }
stage.update();
}
Am I supposed to update all my logic in handleTick()? I would create
my own functions of course, and call it from there. Should the structure
of my program look like this:
createjs.Ticker.addEventListener("tick", handleTick);
function handleTick() {
updateWorldLogic();
stage.update();
}
Somewhere else, I found an example like this:
var canvas = document.getElementById("canvas_id");
startGame();
function startGame() {
stage = new createjs.Stage(canvas);
// NOTE the following comment, I have NO idea what it means???
// We want to do some work before we update the canvas,
// otherwise we could use Ticker.addListener(stage);
createjs.Ticker.addListener(window);
createjs.Ticker.useRAF = true;
createjs.Ticker.setFPS(60);
}
function tick()
{
// update the stage:
stage.update();
}
This code works, but I don't understand the difference between:
Looking at Easel.js docs, you might think that Flip() function is
missing. However, flipping is done using scale with negative
values. To flip image horizontally, use:
image.scaleX = -1;
To flip vertically, use:
image.scaleY = -1;
Before flipping, make sure you set the regX and/or regY to the center
of image. Full example with image sized 120x50:
After ditching many other HTML5 Canvas libs, I was left with Easel.js.
Documentation is sparse, without many examples. I had to google a lot
to find this information, so I'm getting it up here hoping it might help
someone else as well.
If you need a simple graphic (or text) button with hover support,
then Easel's ButtonHelper class is what you need. You can create a simple
image containing 3 buttons states (normal, hover, pressed) and set up
ButtonHelper to do all the work.
Here's how I did it. First create an image with all 3 states. I used
this PNG:
As you can see my image is 300x45 with each state being 100x45 pixels.
Now the code:
// setup
stage.enableMouseOver();
var data = {
images: ["3buttons.png"],
frames: {width:100, height:45},
animations: {normal:[0], hover:[1], clicked:[2]}
};
var spriteSheet = new createjs.SpriteSheet(data);
var button = new createjs.BitmapAnimation(spriteSheet);
var helper = new createjs.ButtonHelper(button, "normal", "hover", "clicked");
// set the button coordinates and display it on the screen
button.x = 100;
button.y = 100;
button.gotoAndStop("normal");
Yes, that's all. If you're looking for example with Text, take a
look at this jsFiddle.
Note that each of the button states can be animated, just add more
frames to the image file and configure the data.animations properly.
In the past couple of days I had determined to select a HTML5 Canvas library
to use for my next game project. Some of the features I require:
Scaling and rotating support with Tweening
Availability or ready-made resource (images, audio) loader or able to easily make your own
Ability to click on a random image or text element (sprite) and handle the event easily, like jQuery 'click' handler
Ability to easily make hover effect over images/text
Some other stuff like Flip is desired by not absolutely required
After investigating a lot of frameworks, I narrowed the list down to:
Crafty, MelonJS, Quintus, LimeJS, CanvasEngine, Cocos2d-hmtl5, CreateJS/EaselJS.
Crafty does not have rotating support, MelonJS and Cocos2d require that you
manually, traverse all the child nodes, find which ones are visible and
hittest the mouse coordinates to get the hover effect. I could not find
this information of Lime.js, but inability to preload audio turned me off.
Quintus apparently
does not support hover at all. So, I was left with CanvasEngine and EaselJS.
RPG.js is moving to CanvasEngine, so I thought there must
be some reason for that and tried CE first. However, elements.events.mouseover
is buggy - the event fires only when mouse stops moving. So, I was left
with EaselJS, and managed to get it to work, even easier than I thought
by using ButtonHelper class. More in my next post...
I decided to try to use Cocos2d instead of jQuery and DOM for my
next browser game. I find Cocos2d documentation confusing, and googling
around you are more likely to get Cocos2d-iPhone documentation that
simply does not apply for some stuff.
I spent a couple of hours trying to understand how to handle mouse
or if it is even possible. I found examples using Cocos2d-javascript
that worked fine, but using the same code with Cocos2d-html5 did not.
At one point I was close to conclude that mouse is not supported as
everything tries to emulate touch. However, this is not the case,
mouse handling works fine.
Currently (Cocos2d-html5 version 2.1.3), the best documentation is to read the file
CCMouseDispatcher.js in cocos2d/touch_dispatcher directory. In your
code, in layer object you can use onMouseMoved and other
methods found in this file. You might need to figure out the
parameters yourself. For example, onMouseMoved returns an event object which
has getLocation() function, which returns another object with x
and y properties. So, the code to draw a custom cursor would
be something like creating the sprite and then updating its position like this:
Now, this would give you two cursors. I tried setting the cursor for
the canvas element to none via CSS, but it did not work.
Another workaround would be to set a transparent 1x1 pixel cursor using
CSS like:
canvas { cursor: url('transparent-image.png') }
I'm yet to try if this works, but somehow I feel it won't. This is all
using Firefox 16 on Linux.
In the past I've always used mysqldump without any additional parameters
to back up MySQL databases. Today I started thinking if it could be faster,
and I found some really useful switches:
--disable-keys - build non-unique indexes after all inserts are complete
--extended-insert - smaller sql file and faster inserts
--add-locks - lock tables while inserting
--quick - dump rows directly from database one-by-one instead of reading into RAM buffer first
I was reading the Facebook developers page looking for information
about the Like button.
Seeing a red flag from RequestPolicy Firefox
extension, I got curious which 3rd party domain is used.
To my surprise, it's Google Analytics:
That's really strange. Facebook is giving Google all the information
about developers using their platform, which Google can then tie that
will other information they already have on the users and target those
developers in the future for any need they might have.
I'm pretty sure Facebook engineers are capable of creating a simple
web analytics tool for their own website, so I'm really confused now.
I'm browsing new Twitter Bootstrap v3, and it looks nice, except for
flat buttons that might not be such a good idea IMHO. I like the grid system
and cool ways to manage HTML tables. And I also found some bugs. Clicking
the Action shows the menu in wrong place:
So, you say LISP is ugly and JavaScript is really cool. And Node.js
is coolest thing on Earth?
I wrote a medium sized Node.js project just for fun. It's about 4kloc of code.
Node.js is nice. After messing with it enough to know what I'm talking about,
I would never use for a regular MVC kind of project. PHP is 5x faster
to develop and 20x easier to maintain if you use a framework like Yii. But,
I would always use it to build real-time web apps. Socket.io is the
best architectured software I've seen in years. There are glitches, gotchas and bugs of course,
as with any fresh software, but simplicity of real time client-server
communication is mind blowing. I don't care about async. crap as PHP with APC
beats Node.js easily in speed/complex deployment ratio.
As for JavaScript itself, we have a love-hate relationship. Whoever
decided that JavaScript strings should be concatented with + operator should be
shot ;) I can live happily with everything else though.
or... How capitalism and communism both failed in search for the
system that would advance the human race most efficiently.
Looking at the state of the world today, all the protests, economic
downturn, debt problems, etc. prompted me to write an analysis of
how capitalism works using simple model with a few actors. I'm a
graduated Economist turned computer programmer, but that's beside the
point...
Imagine a simple world with only 2 people living in it. One of them
has learned how to produce food, the other how to produce clothes.
Let's imagine they both start with the same amount of money emitted
by the central bank.
At first person A produces enough food for himself and for person
B to consume. Person B does not own a land, so he cannot produce food.
He produces clothes instead. They trade food and clothes on par value,
and have equal amount of money after each day.
One day, person A invents a way to produce clothes for himself. The
new process enables him to produce all that he needs and even produce
food required by person B. Person B is out of customers, so he starts
losing money. Soon, person B has no cash left, while person A is
mightily rich. Person B, seeing no way to survive, starts to get angry.
Person A sees that he would lose his only customer, so he invents
welfare. Even if person B cannot contribute to community, person
A sets aside some of his money each day and donates it to person B
so that he would be able to survive.
As you can see in this example, the consequence of liberal capitalism
is that rich would become richer, and poor would become poorer unless
poor are able to invent or produce goods and services that community
requires. The main problem with this is that chances of poor inventing
anything are really low: poor have less money for education, and by
definition don't have resources to finance things like scientific
experiments, which are often required to invent useful technology.
There might be some very smart and bright people who are able to have
a great idea on their own, but percentage of those are really low. Result of this
is that most of the population in capitalism would remain poor. To
paraphrase the movie In Time:
Many have to be poor for some to be rich
Now, I would't have anything against capitalism, as long as I'm on the
rich side ;)
Free market and fair market
In today's markets
all the companies are fighting for profits. Fighting to survive is the
same as fighting to get rich. Most successful companies build products
and services that most of the people want. Now, you can get bigger stake
by either growing the markets share against you competition or creating
new markets. Looking at the most profitable legal industries, you can
see why for example oil companies and pharmaceutical companies are really
not incentivised to advanced the human race. It is better if patient
is never cured, because he stops being a customer. Who in their right
mind would give a customer a product that would make him leave? Oil
companies have all the incentive to prevent any non-oil engine entering
the car market. In fact, many of them are actively searching for and
tracking inventors that might develop alternatives, and are then either
buying or destroying patents. Of course I have no proof for this, but
it is expected. Anyone running such company would have a really big
incentive to do so. Remember from the last post, capitalism is all
about swimming or sinking. This makes market leaders fight and slow
down invention, even when they are inventors themselves. They want
to milk the cow as long as it's possible, before allowing the
human race to progress further. A popular quote says that the solar
energy would become prevalent as soon as the electric companies figure
out how to put a meter on the Sun rays.
Is there a solution to this problem? I don't know. As long as we
live on a planet where resources are scarce, it's questionable. Some
might disagree with me. Famous engineer Jacque Fresco says we could
automate almost everything and all live happily. I'm not sure about
automating dentists, doctors and engineers. Also also technicians
that would need to keep all the engines running. And it still does not
show where the inventions would come from, if everyone can live their
life fully without any incentive to invent new stuff. Except for, maybe,
someone being proud of his invention and showing it off the world.
Communists tried to solve the problem the other way: limit the
amount of wealth one can accumulate. When nobody can get too rich,
they won't be incentivized to do bad things. However, Soviet Union
economy showed another problem with this line of thinking: without
capitalist incentive, there is no desire to invent. In 1990. they
were still producing same models of cars, guns, trains that were invented
40 years before. The progress halted. So, communism does not advance
the human race either.
In short, both capitalism and communism fail to give us efficient way
to advance the human race. Communism gives no incentives to anyone, and
capitalism makes the most innovative companies slow down the pace in
fear of running out of fresh ideas and being overrun by competition.
Having the most powerful companies slowing down innovation is even
harder problem, because they do have the resources to do so easily. They
can influence lawmakers, buy out sole inventors and small companies that
could become future competitors. Given the fact that they are the only
interested party in most cases, they win easily.
Is there a solution?
It seems to me that the only way to fix this problem would be to
reset the human race and have someone implant different principles in
a new generation of humans to come. A generation where greed, jealousy,
laziness and similar traits would be shun upon by everyone and person
would be socially excluded if he tried to exert such behavior. Some
records state that there were civilizations that worked that way: Mayas
and Inca in South America. But, as we all know, conquistadors destroyed
them.
Now, I'm not saying that history should be erased from our heads. In
fact, we need to know it and know why it was wrong and why we need to
prevent such thing happening again. We should be armed against further
conquistadors should they ever come (maybe from outer space, who knows).
I just don't see us transforming our society to this new level gradually
without some cataclysmic event. There are too many powerful stakeholders today
that wish to maintain the status quo. Even experiments like communism
would never had happened if it wasn't forced upon nations by victors of
wars in the first half of XX century (namely WWII and the Russian
Revolution).
In the meantime, quit bragging, embrace capitalism and focus on your
education and inventing new useful stuff. This is the best system we've
got so far.
Today I had a task of installing Slackware 13.37 on HP Pavilion G7
notebook. Install went fine. After installing, I rebooted and somewhere
in the middle the screen goes black without any clue if boot-up is
continuing or not. The fix was rather simple, just add nomodeset
to kernel boot options. If you use standard lilo.conf, it might look
like this:
append=" nomodeset vt.default_utf8=1"
Easiest way to change the setting is to add the option manually while
booting: when Lilo prompt shows up, just type:
Linux nomodeset
When the system boots up, you can edit lilo.conf and then don't
forget to reinstall boot loader by just typing:
Self-driving cars and all that, but simple stuff does not work.
Perhaps wrong engineers are dedicated to this matter. Anyway, I have
account at @mydomain.com and I have @gmail.com address. I'm subscribed
to some google groups (USENET) with @gmail.com. I receive daily digest
of group messages there. When I click the link in this digest e-mail,
it redirects me to google groups page, but using my @mydomain.com account.
There's a nice dropdown to select the account, but once you do, the
context is lost. You would have to navigate to the group page, and then
find the related post buried deep in the stack of messages. I tried to
click again on the link in e-mail after I switched account, but it
reverted to @mydomain after click. I simply gave up in the end.
I'm using MySQL on some of my web servers. I recently started using
node.js and asyncronous queries to MySQL. For this reason, I need to
keep a persistent open database connection. Of course, if that was all
working properly, I would not be writing here. What bothers me is this,
four year old bug, that is officially closed, although it's never fixed:
If you read the comments, it's easy to conclude that MySQL guys are
simply not capable of fixing it, so they decided to ignore it instead.
Nice job!
I'm this close to dumping MySQL and never use it again for
node.js project. Question is: what to use? I'm afraid that Firebird
driver is not really async, and it might be slower compared to MySQL.
Ok, I've finally had it with Tumblr. This blog
was hosted there for about a year. Everything was fine at start, but they
obviously have some scaling issues. In the past few months, the site
simply would not load on first try, but I had to refresh the page each
time. I guess visitors coming here simply assumed the site does not work.
I doubt anyone bothered to press Reload button.
However, recently it broke completely, backwardcompatible.net is
simply not available. I had this blog on blogger, posterous and now
tumblr. They all suck for some reason - I explained all of them in
previous blog posts.
So, from now on, this blog is written in pure HTML, with a couple
of PHP scripts to make the thing maintainable. I don't plan to use
a database, which will make it easier to search and version in Git.
I'll store pictures in Git repo as well.
Now, I know it looks really ugly at this point. I'll fix the design
later - I'm in a middle of another project atm and extracting all
the content from Tumblr's servers was enough distraction for
today these two four! days.
Luckily, API still works, so I was able to wget and then automagically
process XML extract. Otherwise, even two four days
would not be enough.
If you come from PHP background, you're used to PHP's global
top-level functions for everything. Some people say it's PHP's curse,
others praise it. I'm doing some Node.js stuff lately and needed
equivalent of PHP's md5sum() function. Turns out, it's really simple
and included into base Node.js install. You need to use the "crypto"
module and generate md5 hash using createHash. "createHash"
might sound confusing as data is not really hashed by the function.
You create hash and then add data to it. After all data is in, you
read the digest:
var crypto = require('crypto');
crypto.createHash('md5').update(data).digest('hex');
I started developing a small project using node.js with express
and socket.io. Node is a nice server and socket.io is great. However,
I’m having issues with javascript. Currently, two things really get
on my nerves:
1. the plus operator
Most of the hard-to-debug bugs in my javascript code come from
the + operator. It decides to concatenate strings instead of add
numbers. Considering that all stuff that goes over the wire (i.e.
socket.io) is treated as strings, it’s really painful and ugly to
have parseInt(…, 10) everywhere. PHP solves this issue with simple
dot operator. Simple, no-brainer and always does what you expect.
You don’t have to think where does the data come from. Update:
I just discovered that "select sum(...) from ..." in MySQL
also yields a string. Aaargh.
2. foreach
I miss PHP’s foreach so bad. Consider:
for (ix in really.long[expression].toGet.theStuff) {
if (really.long[expression].toGet.theStuff[ix].value < 10 && really.long[expression].toGet.theStuff[ix] > 5) {
...do something
versus PHP’s:
foreach ($really.long[expression].toGet.theStuff as $ix=>$value) {
if ($value < 10 && $value > 5) {
....do something
Of course, one could assign the array element to some local
variable, and so I have local variables all around wasting code lines
and making code error prone (if you need to change the collection you
are iterating, you have to change in two places).
I got my single-domain certificate from Godaddy. Suddenly, I got
myself with .key file, .csr file, and two .crt files. Most examples you
can google on the Internet use self-signed certificates (which is
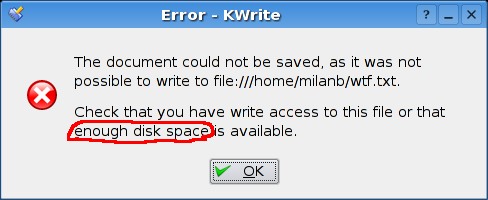
basically useless for Internet use) and .pem files. Wft is .pem,
you might ask?
After wasting hours trying to get this to work, I finally did. I
hope more posts like mine get written and reach google index, so that
people trying to set up production systems don't have to waste time.
Here's how I did everything, step by step:
1. create your private key and certificate-request file. I used the
command suggested by Godaddy as it requires 2048 bit key. Suppose your
domain is domain.com:
Most of the questions that follow are straightforward. Godaddy
suggest you use domain.com
for "Common name" field.
2. log into Godaddy, go to SSL menu and select Manage option.
You actually buy a credit for SSL cert. so you need to "use"
it, and then request a certificate. After using the credit and
pressing "Launch" button I was welcomed with a screen saying
zero (0) in all categories (certificates, requests, credits, etc.).
This was rather confusing. Googling around, I found the solution: go
to credits or certificates even though it says zero. After the page
loads, an option appears to "update" the list. Click this
and your credit shows up finally. Now, you can "request" the
real certificate. Paste the content of domain.csr file you created in
step 1. and wait for GD to create the cert.
3. after the cert is created, download it (there's a download
option on the certificate screen). You'll get a .zip file containing
two .crt files: domain.com.crt
and gd_bundle.crt. First file is your SSL cert.
The second file contains CA certs. of Godaddy that were used to
digitally sign you cert. gd_bundle.crt might contain multiple certs.
of which most browsers only need the first one, but it's better to
install both. I've read some reports that some clients (ex. Android)
require both to be installed properly.
4. Time to add all this to our Node.js/Express setup. It's a
little bit different if you don't use Express (you need to call
http.setSecure() with credentials):
var express = require('express');
var privateKey = fs.readFileSync('domain.key').toString();
var certificate = fs.readFileSync('domain.com.crt').toString();
var dad = fs.readFileSync('gd_bundle.crt').toString();
var app = express.createServer({key: privateKey, cert: certificate, ca: dad});
app.listen(443);
app.get('/', function(req, res){
res.end('Hello SSL');
});
Supplying "ca" field to createServer is crucial, and
missing from most examples on the net since they use self-signed certs.
Now, open http://domain.com and you should see the welcome message.
5. This works fine for my Firefox test. However, if you inspect the
certs, you'll see that only one CA cert. is sent. To send both, we need
to split gd_bundle.crt into two files and tell express to read both:
var dad1 = fs.readFileSync('gd_bundle.crt').toString();
var dad2 = fs.readFileSync('gd_bundle.crt').toString();
var app = express.createServer({key: privateKey, cert: certificate, ca: [dad1, dad2] });
That's all. I hope this saved you some time. In case it did, please
follow me on twitter @mbabuskov, as I will post more Node.js stuff as
I develop my applications.
In my previous post I explained how to set up SSL for Node.js/Express.
Now, I want to serve the same content using the same logic for both
http and https, and I don’t want to duplicate my code.
The idea is to move everything involving Express app. into a
function. Call the function for both http and https server. If you have
global variables, make sure they are outside of this function:
var apps = express.createServer({key: pkey, cert: cert, ca: [dad1,dad2]});
var app = express.createServer();
apps.listen(443);
app.listen(80);
startServer(app, false);
startServer(apps, true);
function startServer(app, isSSL) {
app.configure(function () { // just some sample code
app.use(express.cookieParser());
app.use(express.bodyParser());
app.use(connect.static(‘public’));
});
app.get(‘/’, function(req, res){
if (isSSL)
res.end(‘Hello HTTPS’);
else
res.end(‘Hello HTTP’);
});
}
This works, although I hope there is some nicer solution.
Looks like guys at Google really have trouble with multi-accounts
and sessions. Everything was working fine for months now, but they
messed it up again. What does the problem look like:
I have 2 google accounts, one @gmail.com and other @mydomain.com
I cannot login into @gmail one directly. I have to log into
@mydomain and then use the "switch account" feature
I cannot bookmark both gmails. Although bookmarks are different,
both open @mydomain account
Most other google services I use (ex. Analytics) are tied to my
@gmail account. I cannot access those at all, unless I log out of
everything, clear all the cookies and then log just into @gmail.
My user experience with google is getting worse every day:
multi-account login problems
google docs become painfully slow when spreadsheets grow 300+ rows
(only about 10 columns though)
search is polluted with g+ spam, translation offerings, etc.
If someone build free replacements, I would surely give those a
shot.
I have a contact form on my website. People can leave their e-mail,
so that I contact them back. I set it up so that e-mail is sent “From“
my e-mail address (general rule: never put user’s e-mail in “From“
field), and Reply-to set to user’s e-mail address.
However, when I click “Reply” in GMail, the reply gets sent to back
to me. Looks like some glitch in GMail’s design, and they did not
bother to fix it for a long time.
The solution is rather simple, just change the “From“ field to
some other address you own (different from GMail account address).
For example if your e-mail is office@example.com, you can use
support@example.com in the header. After this little change, “Reply-to“
started working properly.
When DownloadHelper is installed and you open a YouTube video, it gives you
the options to download the .flv or .mp4 file to your computer.
After the file is downloaded, we can use MPlayer to play it and also to
dump the audio. It's nice because it plays both .flv and .mp4, so you just
need one program. To dump the audio to .WAV format use:
mplayer -ao pcm:waveheader FILENAME.flv
This will create file called audiodump.wav. Now, use mp3lame to encode it
to mp3 format. You can also use oggenc to convert it to OGG if you perfer
open formats.
lame audiodump.wav song.mp3
That's all. I put these commands in a simple shell script (video2mp3.sh):
Some time ago I finished reading the Lean Startup book by Eric
Ries. Although I have been using some techniques from it before I have
learned a lot. Yesterday, I found a mention of Rework on some website.
Rework is a book by founders of 37 Signals, which I also read before.
I started to compare the content of Lean Startup and Rework and I
got some interesting conclusions.
Rework and 37 signals business model is really only a sub-set of
Lean Startup philosophy. Basically, Rework stops somewhere during lean
startup process and says "we're content with this". You build
MVP, test it with customers, tweak a little bit and whoa, if you get
good product market fit, what's next? Depends who you ask: 37signals
guys would tell you: "Well done, now enjoy your success".
They refuse to grow business, add features and go for a larger market.
I'm not saying this is bad, sometimes you need to know what is your
field of competence and stay there.
Which one would you follow? It depends on your personality. If
you're going to become a serial entrepreneur, rework is not enough.
If you have an urge to move forward, discover new horizons, you
might need to use Lean Startup in each new project again. After
all, one can hardly call 37signals a startup anymore. They behave
like established business, not a startup. As DHH said on Twist, "if
you're not doing your best idea now, you're doing it wrong".
But, how do you know what is your best idea going to be if you do
not explore? Maybe something looks like my best idea now, and I
should be working on it. But, by the time that project becomes
mature and stable, I might get a dozen of better ideas. And once
I can turn the reigns of the current project to some good manager,
I can go back to "startup" mode and explore new
boundaries.
Some time ago, automatic sending of status updates from one of my applications stopped working. I haven't changed anything on the server, so this was strange. Looking into error message from Twitter:
[request] => /1/statuses/update_with_media.json
[error] => Timestamp out of bounds
well, that's strange. I recall time was moved to DST (daylight savings) Summer time in US recently, and apparently so did Twitter's servers. The rest of the world - bah, they don't seem to be interested, they can barely run the servers for US users apparently.
So, until DST change comes to the rest of the world, we need a hack. At first I thought that Twitter does not like timestamps to be in the future, so I thought about decreasing the timestamp of tweets. That did not work. So, I tried to increase the timestamp and everything is working now. The change is quite simple, just increase OAuth oauth_timestamp by a couple of hours and you're done. In PHP OAuth client it looks like this (I added 5 hours):
private static function generate_timestamp() {
return time()+5*3600;
}
I have measured that in the past week. One of my websites has more than 500.000 user accounts. I picked the users who were not on the site in the last week, because they have already seen the news on the site, and got some 384.000+ distinct e-mail addresses. I needed to contact them regarding an important issue about the website. The e-mail was composed like this:
Hello,
you are reading this mail because you are a member of [mysite link].
Issue explained and link with [call to action]
Regards,
Your webmaster [mysite link]
Links where not plain text, but special URLs I used to track the clicks.
I sent the e-mail slowely over a 7 day period. I wanted to track weekends and working days as well.
I got an interesting problem today. I was supposed to check some
HTML form before submitting to see if the text entered by the user
in textarea has some specific words in it. Googling around I found
a lot of stuff like "how to split text separated by commas"
and such, but I simply wanted to extract words from a paragraph
like this one.
My instinct was to use String.split() function, but it splits on a
single character and I would have to write a recursive or iterative
function to split on all non-word characters. Not being able to predict
all the crap users can enter, this did not look like the right
choice.
Luckily, I discovered String.match() which uses regex and is able
to split text into an array of words, using something like this:
var arr = inputString.match(/\w+/g);
Cool, eh? Now, this all went fine for ASCII English text. But I
need to work with UTF-8, or more specifically, Serbian language.
Serbian Latin script used by my users has only 5 characters that are
not from ASCII set, so I wrote a small replace function to replace
those 5 with their closest matches. The final code looks like this:
var s = srb2lat(inputString.toUpperCase());
var a = s.match(/\w+/g);
for (var i = 0; a && i < a.length; i++)
{
if (a[i] == 'SPECIAL')
alert('Special word found!');
}
function srb2lat(str)
{
var len = str.length;
var res = '';
var rules = { 'Đ':'DJ', 'Ž':'Z', 'Ć':'C', 'Č':'C', 'Š':'S'};
for (var i = 0; i < len; i++)
{
var ch = str.substring(i, i+1);
if (rules[ch])
res += rules[ch];
else
res += ch;
}
return res;
}
If you use some other language, just replace the rules array with different transliteration rules.
Directly load your IDB file from Quicken Home Inventory on any 64 bit Windows system. It works on 32 bit as well, of course. Today, a new version of Attic Manager is released, version 3.00. This version is able to load data directly from IDB files, there is no need to install any additional software. You don't even have to have Quicken installed. This also means that you can run this option on 64 bit Windows 7 for example, or even on Linux.
Attic Manager can also load the inventory data from QHI and MDF files. QHI files are also loaded without any additional software.
For MDF files you need to have Microsoft SQL Server Express Edition installed. This is a freeware from Microsoft that comes with QHIM, so if you already have Quicken installed on the same computer, you don't need to install anything.
In any case, Attic Manager is now unique software on the market, being able to load all Quicken Home Inventory formats and allowing you to keep track of your items on any PC.
I have been using MySQL for a very intensive read-write web
application (averaging 102 queries per second) for more than two years.
I had ups and downs with it, like crazy MyISAM behavior that readers
can block writers AND OTHER READERS. Basically, a table level lock is
issued for read. I have 100+ million records in a table, so it takes
a while to find anything that is not indexed. In the meantime, users
are pondering (102qps, remember) and load goes up so much because
of web server processes queuing like crazy. Ok, I learned not to
do that anymore. I now use binary logging, restore to a different
server and query there. Maybe a switch to InnoDB would be a good
idea, but in this case I'd rather use a serious MVCC database
like Firebird. Why, you might ask... well, here's one of many
reasons, the one that prompted my to write this:
In Firebird, I can happily do this:
delete from atable a1
where exists (
select 1 from atable a2 where a1.data = a2.data and a1.id <> a2.id );
It just does it, and fast, because index on primary key field ID is
used. In MySQL, to quote the manual:
Currently, you cannot delete from a table and select from
the same table in a subquery.
Come on, this is one of the most basic database operation. So, what
am I now to do? Waste my time dumping the list of IDs to delete to some
temporary location, and then iterating that list to delete. :(
A few years ago I discovered screen, a nice Linux tool that
enables you to detached from terminal with commands running and all in
the background. You can even connect later from a different computer
and continue where you left off. I initially used it for rtorrent,
but now I also use it to administer remote computers, for example
when I start to do something that might take more than a day, I can
log back in tomorrow. Also loggin in from home/work to complete some
task, etc. Another use is administering remote computers on dial-up
(yes, there are some) or slow and unstable 3G connections. Even
if connection breaks down, I can log in later and pick up where
it stopped.
One of the annoying "problems" with screen is that
shift+page up/down does not scroll the buffer. This is due to the
fact that screen has its own buffers. To work with them you need to
enter the "copy mode" using Ctrl+a followed by [.
Since I use non-English keyboard that's Ctrl+a, AltGr+f. Hard to
remember when you don't use it often.
I use Konsole, and I found a way to make it work by adding the
following lines to .screenrc (in my home directory):
Beside being free (both as beer and also open source), you don't
need 24x7 DBA and there are generally less headaches. Here's a nice
example explained by Norman Dumbar in a mailing-list post. Norman
administers over 600 Oracle databases and about 40 Firebird ones:
Oracle uses log files for REDO and has ROLLBACK_SEGMENTS or UNDO
Segments (depending on Oracle version) for UNDO. It never uses log
files for UNDO - and UNDO is what provides Read Consistency/MVCC
in an Oracle database.
Changes are written to the LOG_BUFFER
(n memory) and periodically - on commit, every 3 seconds max, or when
the buffer is 33% full - flushed to the REDO logs. These REDO logs might
be archived to disc when they fill up. That Depends on the database archive
log mode though.
These logs are used when a database is restored
and rolled forward (using the RECOVER DATABASE command, for example).
In order to roll back changes and to ensure read consistency,
UNDO is used. These do live on disc - as tablespace files - but remain
in memory in the buffer cache alongside data blocks etc.
When
a SELECT is started, the data returned are the data from the data blocks.
Each row in a block has an indicator that tells when it was last updated.
If a pending update is taking place (currently uncommitted) or if a
commit has taken place since this SELECT started then the data read
from that data block has changed - and is not consistent with the
start time of this SELECT transaction.
When this is
detected, Oracle "rolls back" the changes to the start
time of the SELECT taking place by looking for the UNDO block(s)
associated with the transaction that made the changes. If that
results in the correct (consistent) data, that's what you get.
If it turns out that there were other transactions
that also changed the data, they too will be detected and
undone.
In this way you only ever see data that was
consistent at the start of your own transaction.
As
long as the DBA correctly sizes the UNDO tablespace and correctly
sets the UNDO_RETENTION parameter to a decent enough value, data
changes are able to be rolled back happily all the time.
If the DBA failed miserably in his/her duties, the
"ORA-01555 Snapshot too old" errors are the result. And are most
irritating. Long running SELECTS - batch reports for example -
tend to show up this error mostly.
Of course, you would never see such problems with Firebird, because
the old record versions are stored in database and not the log files.
You don't have to care if system crashes - after reboot it simply
works.
You might think that engineers who build Firebird are smarter
than Oracle's but sometimes I think Oracle is deliberately made
so complicated to require DBA and also offer them job security.
And also makes sure nobody can complain it's too easy to use.
No, Quicken does not support 64bit Windows 7 yet. And there are no plans to do so. A few months back, GuacoSoft has released a new version of Attic Manager that is able to load data from Quicken directly. You can then export it into csv, excel, whatever OR simply use Attic Manager to manage the inventory.
Initial version of Attic Manager with this support (2.03) was only able to load data from .MDF files. However, a new version (2.50) is out now that supports .QHI files as well. It can load all data from .MDF. For files with .QHI extension, it loads all the data except image thumbnails. However, if you still keep your original images on the disk in same location where they were when you loaded them into QHIM, the Attic Manager will pick them up while importing and create thumbnails automatically. Not only that, but it will store a copy of each image into it's database, so that you never lose it in the future.
So far, this is the only way to extract data from Quicken, and it's really the only Home Inventory program on the market that enables you to transfer all your data before migrating to a new program.
Looking for a way to report a problem with YouTube software I
found a link "Report a bug" a the bottom of the page.
However, when I clicked it, I got redirected to:
When logging from my laptop to remote SSH servers I had a strange problem. Whenever a big chunk of text needs to be returned, my SSH session would stuck and completely stop working. It would not disconnect, but just stay there doing nothing. I would have to log in again. By "big chunk" I mean something like 20+ lines. Output of "ps ax" for example.
This made me so mad, because if was working on server for a few minutes making sure that I "head" and "tail" every command to reduce output and then I would forget that some command might output more. For example, using "vi" or "mcedit" was completely impossible.
My Internet connection goes through PPPoE. Websites work fine, HTTP works really well, but SSH... no go. The server on the other side is behind a firewall, so tunneling and port forwarding are here.
I searched around, and found that TCP/IP packet size might be the problem, so I tried different MTU values for my PPPoE connection, but without much luck. I was able to get a little bit more before it would stuck again.
And then I landed on this Debian bug report from 2005:
Apparently still valid. It looks like it only relates to some D-Link routers, although I have no clue what's at the other end where the server is connected. The solution is to reduce MTU server-side. Luckily, I can still run a one-liner command, and so I did:
/sbin/ifconfig eth0 mtu 1000
Everything runs fine now. I just wonder if this would decrease server through-output on the local LAN where it runs.
Recently I switched my main website from 2-core AMD 4GB RAM machine to 8-core 16GB RAM Intel i7 one. I also switched from CentOS 5 to CentOS 6. I set up everything the same, but suddenly the system was using much more RAM than before. And I'm not talking about filesystem cache here. I thought that increasing RAM would only increase filesystem cache, but something else was occupying RAM like crazy. Looking at output of "free", "top" and "ps" I simply could not determine what eats RAM because running processes were fine.
So, I googled a little bit, and found that problem was in dentry cache used by Linux kernel. You can see the kernel memory usage with "slabtop" command, and my dentry was crazy, something like 5GB and growing. Googling even more, I found horror stories about servers going down, OOM killing vital processes like Apache or MySQL, etc. So I wanted to stop this.
Quick fix is to clear the cache manually. Some people even "solved" this problem by adding the command to cron job.
echo 2 > /proc/sys/vm/drop_caches
On the MRTG screenshot you can see the dentry cache size in megabytes marked as a blue line. 4000 means 4GB of cache. I have 16GB, remember. When you run the drop_caches command above, you get the effect marked by the red arrow.
I did not like the approach of adding this to crontab, so I investigated further, asked at mailing lists, learned that Linus himself says that "unused memory is dead memory" and that's why kernel is hungry. Still, I decided to reduce the hunger and added this to /etc/sysctl.conf
vm.vfs_cache_pressure=10000
That did slow it down, but it was still growing. You can run sysctl -p to apply changes to the running kernel without restarting. Next I added these as well:
However, it was still growing, and I decided to leave it be and see what happens. Is my server going to crash, become unavailable, or something. 24 hours later, dentry was again going up like crazy and suddenly it dropped. By itself. See the blue arrow in the screenshot. It seems like kernel figure out that RAM is going to be exhausted, filesystem cache would be reduced, etc. After this point, everything went back to normal.
I tried this experiment again, about a week later, with same results. High-rise, drop and things going back to normal. So, if you're worried your dentry cache is growing like crazy, don't. Just tweak those settings in sysctl and wait for at least 48 hours before drawing any conclusions.
Today I learned about interesting issue with newer versions of Firefox (I use FF7). It has a nice web developer-friendly feature to disable alerts. This is really useful when you place alert() by mistake in some loop and you can't get out because as soon as you click OK, you get another one.
New Firefox has a checkbox to disable future alerts. And this is great. So, what's the problem? Once you disable alerts, and javascript code is executed that would display it, it does not keep running, but rather throws an exception. This does not look like correct behavior to me.
Imagine a web application that alerts user about something and then keeps running to finish the job. If user disabled alerts because he was in a hurry and clicked fast on different message boxes, the script would not keep going but stop. And there is no way to revert that short of reloading the page (yikes!).
I found a workaround, I created a function called tryalert that wraps the alert in try..catch block. It looks like this:
function tryalert(message)
{
try { alert(message); } catch(e) {}
}
This is a fine workaround. Now instead of alert() I call tryalert() and although the alert is not displayed anymore, the code keeps going as if user has been alerted.
The problem is introducing tryalert to ALL applications I've written so far. It's impossible. I hope Firefox team changes this.
Unfortunately, Quicken Home Inventory does not work on Windows 7,
and you might have a hard time switching to another program because
QHI does not have an option to export the data.
However, there's a way to work around this. A program called Attic
Manager, can import the data directly from Quicken database, even if
you don't have Quicken installed. It even works on 64bit Windows.
You just need to have your QHI.MDF database backup file.
Once data is in Attic Manager
you can export it to CSV format which can be imported into Excel,
OpenOffice and almost all the other Home Inventory software. Or,
maybe once you try it, you would stick to using Attic Manager.
If you are looking for a way to use all the data you have already entered on Windows 7 box, you came to the right place. Although the short answer is: "you really can't do that with QHI", there is an easy solution to this problem...
It can load locations, categories, items and images (photos) of items.
Most importantly, it runs on all modern operating systems including Windows 7 and various Linux distributions.
If you don't have access to your old copy of QHI or Quicken Classic, it does not really matter, because Attic Manager can load the data directly from QHI database.
P.S. If you decide to buy it, use the coupon code CNVRT4 to get 40% discount off the price.
I had a application using wxWidgets 2.8.0 and then 2.8.8 in
production. There were some bugs in earlier wxWidgets versions on
Linux, so printing was not working properly. I decided to upgrade
wx and that fixed it. Now I wanted to use the same version for
Windows version of my application. I originally used some (now old)
MinGW version and just wanted to rebuild and be done. But, I got
build errors instead. I don't really last time wxWidgets failed to
build so I asked at mailing list and finally dug into the source
code myself.
It looks like wx code is all fine, but there are problems in
MinGW headers. I particular, you need to edit the file
C:\MinGW\include\winspool.h and change
DocumentPropertiesW function's signature from:
LONG WINAPI DocumentPropertiesW(HWND,HANDLE,LPWSTR,PDEVMODEA,PDEVMODEA,DWORD);
to:
LONG WINAPI DocumentPropertiesW(HWND,HANDLE,LPWSTR,PDEVMODEW,PDEVMODEW,DWORD);
It seems to be already fixed in newer MinGW versions.
I have a server where nginx is used as frontend for Apache. nginx serves static content and Apache serves PHP pages. This is a common setup.
Today I migrated stuff to a new server and needed to copy a 7GB database file to another server. I figured HTTP would be fastest way to do it. Unfortunatelly, DNS change already went thought so I could not serve the file on the static domain nginx was configured for.
I thought nevermind, placed file under one of those domains handled by Apache and started the download. It was going fine at 11MB/s for some time. However, soon it started to crawl at 850KB/s. I suspected network problems, but everything else was running fine. I looked at process list and whoa, nginx using 99% of CPU. Because of this single download, the server was brought to its knees and no other client could even get a simple Hello World page.
I stopped the download at the client side and nginx soon recovered (not restart needed). Then I edited /etc/hosts and place the old IP address of static domain and continued the download (wget -c). It finished few minutes later with 11MB/s average.
Both me and my colleague work separately working on same git tree
while being offline for a couple of days. Result: following "git pull"
I got a huge conflict spanning about 100 of files.
This meant that manual resolution is out of question.
Enter "git mergetool" and "kdiff3". I installed kdiff3 from
linuxpackages.net (version is for old Slackware 11.0, and I had to s
ymlink /opt/kde/kdiff3 to /usr/bin/kdiff3 so that git finds it).
git-mergetool calls kdiff3 for each file, you merge and save.
Job done very quickly.
Seems to be a fine day at Google today, perhaps engineers are pulling hair.
This morning, I was looking at a spreadsheet in Google Docs and suddenly some 20 values simply vanished right before my eyes. I wasn't even working anywhere near that part of the sheet. I was inserting new values at bottom and somewhere in top-right corner the values were gone. I tried undo and to scroll around (big sheet) and only when I switched to another sheet and came back the values showed up again. Phew. From now on I'm doing export and download to my computer every time I finish editing.
Few hours later, a new issue. Looking at a spreadsheet I selected Save from the menu. It said that it's ok. I did some changes, clicked Save, got no error but the screen read "Last saved 2 minutes ago". Ok, maybe it's just a minor glitch. 15 minutes later I tried to save again. Once again, no errors, but it still says "saved 17 minutes ago". At this point I was confused whether save is not possible or the message is simply wrong. I exported the document to xls format, checked in OpenOffice and then closed the browser tab.
Three strikes and blog post is out. I just had another issue, now with GMail, so I guess it's time to make all this public. I wrote an e-mail message and it said "Your connection to GMail has expired. Please log in again." Ok, it's not like I haven't seen that one before, but it's been almost a month. I though they had it fixed. I logged out, logged back in and... it still does not allow me to send an e-mail. I can read messages fine, but as soon as I try to post, I get a warning that "Your connection to GMail has expired. Please log in again.".
Oh well, I guess we get as much as we payed for it ;)
I have been stackoverflow user almost from the very start of the
website. I recall reading some Jeff Atwood's blog posts and thinking
how naive he is. He has a classic case of Microsoft fanboy-ism. He
swears by .net and MSSQL server and spits on Linux, PHP and... well...
entire LAMP stack.
When stack became popular the website started to get a lot of
traffic and Jeff was all like "Oh we don't need all the scaling
technology that all the web companies have developed since web 1.0
till today. We're smarter, we use the all-powerful Microsoft stack,
we'll just buy more RAM, more CPU and keep it all on single machine.
Machines are so powerful these days and cost almost nothing". How
little did he know.
As more and more people use the website it seems that they reached
the limit of what is possible. Stack website is now inaccessible for
days. By inaccessible, I don't mean that the site does not open. It
just open waaaay too slow to be usable. I sometimes wait 5 minutes
to get the home page.
What I really regret is all those dumb readers on Jeff's
codinghorror blog, and all those fanboys on stack website. Some
people tried to tell Jeff that this would happen, but he would not
listen. He was very arrogant and dismissed all that as LAMP-crap. All
his followers blindly followed his thoughts as if they really wanted
that to be true. Psychology of a herd, I'd say.
Oh well, too bad that public access to such valuable resource
is now limited because of stubborn owners. Maybe it's time for a
real competitor to step up, with a simple slogan: "just like
stackoverflow, except that it really works".
For the game I'm making I have a bunch of array which represent
a puzzle player needs to solve. Ensuring puzzle is solvable is CPU
intensive, so I pre-calculated a couple of thousands of puzzles and
select one randomly. Since puzzles are static data which is not going
to change, I decided not to burden the database with this because DBMS
is always overloaded with other stuff anyway.
My first thought was to build a big array and fetch a random element. I
found some benchmark showing that this is faster than "if" or "switch", however
benchmarks excluded time needed to parse/create the array itself.
Since every player is a new HTTP request, this huge array would
have to be constructed each time. I am using APC, but I failed to
find if arrays in precompiled PHP source file are stored "structured"
as well.
Dropping the array idea, I though about "switch", foolishly
thinking that it would use some kind of jump-table and run the
desired return statement. Something like this:
function get_puzzle($id)
{
switch ($id)
{
case 0: return array (...first puzzle...);
case 1: return array (...second puzzle...);
case 2: return array (...etc.
However, researching this I find out that switch performs
similar to series of "if" statements... variable is compared
with each "case".
So I decided to roll my own solution using "if" statements,
but not linear. I used a B-tree approach. Split by two until
only one is left. This means it would take only 11 comparisons
to reach a puzzle from a set of 2048. Here's an example with
set of 256 puzzles.
function get_puzzle_btree($id)
{
if ($id < 128)
if ($id < 64)
if ($id < 32)
if ($id < 16)
if ($id < 8)
if ($id < 4)
if ($id < 2)
if ($id < 1)
return array (...first puzzle...);
else
return array (...second puzzle...);
...etc.
Of course, I did not write this "if" behemoth by hand. A
simple 20-line recursive function spits out the PHP code.
In the end, I wrote a simple comparison loop that tries to
get all the puzzles and compares whether the old "switch" and
new "btree" function return the same values.
I had a client's machine installed with Windows 7 and some free
hard disk space for Linux. I decided not to install the Linux boot
loader because:
I did not have Windows install/rescue CD at hand
in case something goes wrong I could not boot into Windows
I had some experience in the past with Windows XP where it simply did not work
Since re-installing Windows or even fixing Windows if it became
unbootable was not an option, I decided to play safe: use Windows'
boot loader to boot up Linux.
I did this in past with Windows XP. Basically, you save Linux boot
loader into some file (it's only 512 bytes) and then tell Windows'
boot loader to load it. On WindowsXP this means editing boot.ini
file in C:\. To create the linux boot loader file, install linux
boot loader into root partition (for example, with LILO, if you
installed Linux in /dev/sda4, then lilo.conf should read
boot=/dev/sda4) and then read the first sector into a file:
dd if=/dev/sda4 of=linux.boot bs=512 count=1
This will create file named linux.boot which you need to
copy to C:\ disk of your Windows machine (use the USB stick or
network for this).
On Windows7 there is no boot.ini, you have to use Microsoft's tool,
named BCDEdit. BCD stands for Boot Configuration Data. You need to
run BCDedit as administrator. Hit the Start button, then go to
All programs and then to Accessories.
Right-click the Command prompt and
"Run as administrator".
Once upon a time, there was this kid that wanted to know about recursion. His father told him:
Son, once upon a time, there was this kid that wanted to know about recursion. His father told him:
Son, once upon a time, there was this kid that wanted to know about recursion. His father told him:
Son, once upon a time, there was this kid that wanted to know about recursion. His father told him:
Son, once upon a time, there was this kid that wanted to know about recursion. His father told him:
...
ok, now we're five levels deep into recursion and also have 5 items (father+son stories)
on the stack. Once a father decides to change the story to end it instead of recurse further,
the stack will unwind and function at the top (this blog post), will end.
I’m creating a gaming website and one of the games has a
complex CPU-intensive AI. Many possible positions for player and
computer need to be examined before heuristics can do their work.
For this I stack the game state, play a hypothetical move and run
AI on it again. The number of moves it looks ahead is configurable,
but the more there are the number of possible combinations grows
exponentially. This will run on the web server, so it has to
consume as little CPU as possible.
The rest of the website is written in PHP, but I started considering something faster for this. Of course, when you want to go fast, you want C or C++. I know some Assembly as well, but it’s PITA to use. But, before “wasting” any time in using C and having to set up the compiler to build the executable for target server, I wanted to make sure there is a reason to do it.
The benchmark is very simple. An array and a big loop doing trivial stuff with it:
------------------- bench.c -------------------
int main(int argc, char** argv)
{
int i,j, arr[10] = {0,0,0,0,0,0,0,0,0,0};
for (i = 0; i < 100; i++)
for (j = 0; j < 1000000; j++)
if (arr[i%5+j%5] == 0)
arr[i%2+j%2] = 1;
return 0;
}
-----------------------------------------------
I compiled it with GCC 4.2.3. Here’s the PHP version:
------------------- bench.php -----------------
$niz = array(0,0,0,0,0,0,0,0,0,0);
for ($i = 0; $i < 100; $i++)
for ($j = 0; $j < 1000000; $j++)
if ($niz[$i%5+$j%5] == 0)
$niz[$i%3+$j%3] = 1;
I run it with PHP 5.2.5 cli
Now the results:
$ time -p php -f bench.php
real 97.32
$ time -p ./bench
real 2.11
Amazing! C seems to be 46 times faster. I must admit I really
expected better results from PHP. I wonder if there is some way
to improve PHP speed on this one.
My I guess was that
PHP’s excellent duct-tape arrays come with a price. To
check this, I removed the array access, leaving only the
for loops inside:
$ time -p ./bench
real 0.33
$ time -p php -f bench.php
real 15.14
Looks like array access is not to blame. It is consistently
46 times faster.
Tests were done on Intel Core2Duo CPU clocked at 2.16GHz running
32bit Slackware 12.1. All the results are averages of 10 runs.
More often than not I find myself in situation to want to post something to a website forum I have been following for a long time. Latest example is today with HackerNews. I have been reading HN for about 6 months and today was the first time I was compelled to post something. I was able to comment the existing threads right away (which is nice), but not able to post a new link - most probably because my account was 10 minutes old.
By the time I earn privilege to post the story it wouldn’t be relevant to anyone anymore. Lesson learned the hard way. So, make sure you create an account for the website you are using daily, even if you don’t think you’ll ever need it.
Don’t you just hate how spammers have ruined the Internet.
I
just lost a couple hours on this. I’m making a puzzle game in HTML, so I used table to split an image into pieces and display each part at correct place. The problem is that I get weird space beneath every image, as part of TD tag. I tried everything, setting border, cellspacing, cellpadding to zero, playing with CSS margin, padding and display type. Nothing worked. And problem was visible in all browsers.
So I started to create a simple test-case in order to ask question on some programming forums or stackoverflow. However, my sample was working properly. Removing stuff part-by-part from the more complex case I got to the point where everything was the same, but nothing worked. And then it occurred to me. HTML document template was created using an editor that inserts DOCTYPE automatically. It was set to XHTML Strict. Removing the line fixed everything.
So make sure you use non-strict XHTML, or even better HTML in quirks mode. Maybe it sounds “dirty” but it sure saves the time and nerves.
At our company we manage 100+ Linux computers remotely. Those are mostly clients for our ERP application, and sometimes you simply need to log in to fix something or help the user. Most of them are behind the firewall. In the past, we always had a deal with client’s IT staff to open a certain port on their firewall and forward it inside to SSH port at our machine. This works nice, but there are cases when IT guys have a hard time setting it up, or when ISP is simply blocking any possibility of doing so.
Last year I managed to set up reverse SSH to work around this. How this works? Basically, you need to have one publicly accessible server. The remote client logs into it using SSH and then opens a TCP port locally (on the server). After that, you can ssh to that port on the server machine and it tunnels back to ssh server on the remote workstation.
This was easy to set up manually, but we need a permanent connection. You can place the ssh command in some script at the client and make sure it runs, but there are times when this does not work so robust. Especially over mobile (3G, GPRS, EDGE) connections SSH session gets dumb and although it looks alive there it does not send any data back or forth.
Enter autossh. This great program starts the tunnel (no need to remember all the parameters to ssh client) and makes sure it stays up. Every 10 minutes (configurable) it checks if connection is still alive, and restarts it if data cannot be sent.
I guess this will not be the first nor the last text comparing those two frameworks, but I got so amazed with Yii that I have to write it.
Let’s be clear, CodeIgniter is just a little bit more of a simple MVC framework. Yii is a complete web-development framework used for rapid web application development. Let’s compare them in detail…
CodeIgniter is great for beginners. If you barely have a clue what MVC stands for, I highly recommend it. It features great tutorials and is super-easy to learn. If you want to learn what MVC is and how to use it, take a look at CodeIgniter video tutorials. CodeIgniter enables you to go into coding really fast and create basic stuff quickly. But, that’s all. It’s great to learn MVC, and it works fine even for large websites. However, you have to do a lot of things by hand. If you’re experienced PHP developer you might even be used to that and you won’t see anything missing in CodeIgniter.
I built a couple of websites using CodeIgniter, most visited on is slagalica.tv with about 30k visits/day.
From 2009 on I was testing Yii, but I only got to use it for the real project last month. Be prepared, if you are not experienced with MVC frameworks, you might find the learning curve really steep. Yii is very powerful, but to harness the power you need to learn all the features and the way stuff is done in yii. Instead of just going in and coding, take some time to read the docs, wiki and create some simple small project to learn it. Whenever you are doing something that seems like too much manual work, look for ready-made yii-way solution.
So, what makes Yii so much better? I don’t know where to start, so I’ll just enumerate:
Gii code generator. Gii can create template models, views, controllers and forms. The special case CRUD really makes it stand out. You simply give it the database table name, and it creates model with all the attributes. You just define data type (numeric, etc.) whether field is required, and those rules get applied ALWAYS when you try to save/update the data. In CodeIgniter, you need to validate it on each action. The difference is that CodeIgniter is form-oriented while Yii is data-oriented
Form handling. Gii generated forms use “active” fields. This means that when some field is not validated, yii would display the same form to fix the problem with all the data filled in
HTML Grid component. Enables to display data in tabular way with automatic sorting, paging, coloring of even and odd rows, etc.
jQuery integration. This means that stuff like date-picker or auto-complete input boxes are usually one line of PHP code and Yii spits out all the required Javascript, HTML and CSS code.
Translations. Creating multilingual websites in Yii is really easy. With CodeIgniter you would have to create your own way of doing it.
Database relations. Yii supports lazy loading. This means that you don’t have to write JOINs each time you need to get a value of related table (for example: name of author of a blog post). If you have a ActiveRecord instance of blog post as $post, you simply refer to author’s name like this: $post->author->name. Yii would execute the needed SQL to get it.
Consistency. Yii is much better choice if you have multiple developers working on the project. Yii introduces rules how stuff should be done, and there is no reinventing the whell. This means that all developers create the code that others can pick up easily.
Example of site I’m building using Yii: setlopta.com. There’s a link to English version in top-right corner.
I’m using Git to track source code changes and I host most of my websites on servers where I have SSH access. I never liked ftp much, so I’m using SCP to upload all the files.
One of the main tasks is to upload the source code files that have changed since the last release. To do this, I first use gitk to find the last revision that got uploaded to the server and then diff the changes. For new files and directories, the script also creates them on the server. So, I would use script like this:
source difference.sh 12edf98
where “12edf98” is a version hash from git. Short version of “source” command is dot (.), so this is the same as above:
. difference.sh 12edf98
The difference.sh script creates a script that can be sourced again to actually make it run. So “difference.sh” will show what would be done and “upload.sh” does it. This is the content of “upload.sh”
eval $(source difference.sh $1)
I run it like this:
. upload.sh 12edf98
And here’s the content of difference.sh (watch the line wraps):
echo echo Creating new directories if required ";"
for i in `PAGER=cat git log --reverse --pretty="format:" --name-status HEAD...$1 mysite.com | grep A | cut -c44-1000 | grep / | sed "s5/[^/]*\\$55" | sort | uniq`; do echo echo $i ";"; done
for i in `PAGER=cat git log --reverse --pretty="format:" --name-status HEAD...$1 mysite.com | grep A | cut -c44-1000 | grep / | sed "s5/[^/]*\\$55" | sort | uniq`; do echo ssh mysite.com mkdir --parents /var/www/html/mysite.com/$i ";"; done
echo echo ------------------------------ ";"
for i in `PAGER=cat git log --reverse --pretty="format:" --name-status HEAD...$1 mysite.com | grep -e "[A|M]" | cut -c44-1000 | sort | uniq`; do echo scp mysite.com/$i mysite.com:/var/www/html/mysite.com/$i ";"; done
All the website files are stored in directory called “mysite.com” and scripts are one directory above (same level as mysite.com directory).
I lost a lot of time finding information on the Internet to make all this work, so I hope it will help someone.
Today I got sick and tired with problems of posterous.com, the service I used to host my blog. I heard Tumblr is really good so I decided to give it a chance. My first test is whether I can post the source code snippet, which is very important to me because I often post code samples.
Today I noticed something really strange. I’m logging into my GMail
account, and the login page redirects the browser to some youtube.com
subdomain before redirecting back to my inbox.
Looks like now I can “like” YouTube videos without having to log in! Hurray!
Although this is a strange way to make it work, I appreciate the
end-result even if it means one more redirect. I just hope Google
won’t do the same for all their services, because having a dozen
redirects before logging into GMail would really be bad.
Almost each day I’m facing obstacles that cut my workflow,
make me go around or just make me go mad. Here are some that
repeat every once in a while or just happened recently:
1. Firefox crashing
2. Google Apps multi-login failure
3. Linux terminal
4. Liquidweb routing
5. Xorg server killing keyboard
6. stuck SSH sessions
Ok, let’s go into details:
1. Firefox crashing
One of the best features Firefox has is crash-recovery, and that with a
good reason. However, it still is not perfect. It happens often that I
have 10+ tabs open, one of those crashes FF and when I restart all my
GMail sessions are lost (see point 2. for more pain), I have to log in
again. Same with some other websites. Sending report to mozilla takes
forever, and even though there are sites I reported like 50+ times
while using FF 2, 3, 3.5 and 3.6, it still crashes FF 4. I wish Chrome
was easier to install on Slackware and if it had all the extensions I
needed (TamperData, Firebug, RequestPolicy, Screengrab are a must)
2. Google Apps multi-login failure
Having to log into accounts in exact order is painfull. What’s
even worse, once browser saves the cookie it is impossible to login into
any of domain-based accounts directly. You have to log into regular
GMail account first. Maybe I should take a job offer to go to work for
Google and help them fix this ;)
3. Linux terminal
I spend about 20% of my working time in terminal, mostly using ssh to
access remote computers or using make to build/install programs and
packages. KDE’s Konsole is the best tool I used. However, these is one
problem with resizing. I still haven’t been able to determine the
exact way to reproduce it, but switching from 80x25 to fullscreen at
some point starts a strange behavior. Parts of typed text get lost,
overwritten. This happens only when command cannot fit in 80
characters. Maybe it happens when you get one command that is too long
for the fullscreen terminal, and after that something gets messed up.
I never managed to catch it, but it does annoy me. The only was to get
proper line wrapping back is to normalize the window size so that the
terminal is 80x25 again and then you should forget about fullscreen
until you log out and log in again.
4. Liquidweb routing
For more than a week, there has been some routing problem in
Liquidweb, and it does not look like it’s going to be fixed any time
soon. Searching on Google yielded some results, i.e. other people see
this problem, but it seems to be only sporadic in US, and I guess LW
does not care about the rest of the world. Some of my websites are
hosted at DTH and I’m accessing from Europe. Using some different ISP
in Europe makes it work, but traceroute shows completely different
path that does not go through LW at all. To cut the story short, I
don’t have access to our main bug/issue tracker, 3 company websites,
and one web service I’m using. I have to build SSH tunnels to my other
servers and reconfigure my local system to deal with this. It’s not
unsolvable, but it’s a major PITA.
5. Xorg server killing keyboard
When I’m working all day at full speed, I get this at least once. It
only happens on my 2 desktop computers, the laptop running same
version of Linux kernel and Xorg works just fine. At some time the
keyboard simply stops responding. I can you the mouse though. I tried
replacing the keyboard, mouse and motherboard, problem is still here.
This leaves the only conclusion: it must be software. It’s either
Linux or Xorg. My guess is Xorg, because I can use mouse to log out of
KDE, and then keyboard magically starts working again and I can type
password at KDM login to log back in.
6. stuck SSH sessions
I guess there is some configuration on my client’s network routers to
simply “lose” stale network connections. I log in via SSH and some
20-30 minutes later the session is stuck. The connection is not
dropped, it just stays there, waiting.
Do you have some stuff that really get’s on your nerve on a daily
basis? Please share…
I just got a CAPTCHA for a link I wanted to share on Facebook. WTF? Maybe I should be using twitter after all.
However, the big problem is that CAPTCHA dialog doesn’t really work. I’m using Firefox 4, the CAPTCHA words show for a few seconds and suddenly entire dialog is gone and I only have Submit and Cancel button. Of course, trying to submit fails the test and dialog pops up again … with the same problem.
Facebook developers should really test stuff before going into production.
I have 4 domains using google apps accounts and been mostly using e-mail on them. Today some of the domains switched to new whatever and multiple-domain feature started to wreak havoc. I was able to use multi-account for about a month until today. Even that was a major PITA as I had to log into accounts in correct order, otherwise you get the darned “page is redirecting is such way that … whatever”.
Now, I have even funnier stuff happening, I wrote a 4 page long e-mail and when I try to send it, “my session has (mysteriously) expired”. Copy/paste the email to a text editor and re-login into google apps. Well, not so simple as I had to close Firefox completely first.
Another “cool” thing was when I opened my inbox, clicked the first unread message and voila, “my session expired”. WTF?
Combine that with 100% CPU usage when writing long e-mail messages, turning € symbol into word EURO, preventing some types of attachments, and, recently too agressive SPAM filter that eats most of my mailing-list mail. GMail might be a nice product, but I certainly see a lot room for improvement.
So, for the time being, Google Apps is dead to me. I’m looking for an alternative. If I’m unable to find something worthy, I might switch back to using Thunderbird and setting up my own IMAP (or whatever) server, or even building Google Apps competitor myself. It doesn’t have to have all the bells and whistles, but basic stuff must work flawlessly.
I decided to automate conversion of MySQL database to Firebird. I got tired of manual find&replace process, and created a small parser that changes from MySQL to Firebird syntax. Currently it only supports database structure dump (no data, only structure) from PHPMyAdmin. Not all datatypes are supported, but feel free to “fix” it. It’s written in PHP and it’s open source. It would be great if you would send back any modifications you make. Download it here (source code included):
Please note that this is quick&dirty converter, so make sure you test the output before using it in production. It does support some tricky stuff like auto increment columns and LAST_INSERT_ID. There is a stored procedure for this at the end of the script, you can call it like this:
Once you create the Firebird script, make sure you search for text WARNING: which might indicate some incompatibilities. For example, Firebird does not have tinyint, mediumint and unsigned datatypes. Also, check for TEXT and LONGTEXT. I’m using UTF8, so I converted those to varchar(8000), which might not be what you want. Maybe BLOB SUB_TYPE 0 would be a better choice, but I don’t like PHP support for it, so I’m using varchar instead. Maybe some command line options could be added to the tool to support different behavior.
This program covers all the databases I had to convert so far. If you are interested in improving it, please contact me.
I’ve been using gmail account for personal stuff for some years now, and I also have a google apps account for company domain. I the past I was able to log into both using the same browser in different tabs. In 2011 all apps accounts will be upgraded to new software, so you can use them as regular google accounts. This is great, except there’s one bug that makes this change actually bad: you cannot be logged into 2 accounts at the same time. This means that I cannot read personal e-mail and company e-mail at the same time. Now I could run 2 browsers, but I’ll really a shame that Google with all their engineering potential cannot make this simple thing work properly.
I started using wxWebConnect by Kirix in one of my applications and ran into problems with printing. When using the latest XULRunner 1.9.2.10 the Print() function would not work at all. Looking into wxWebConnect code, it seems that it did not manage to get either of settings for XULRunner 1.8 or 1.9. First I thought about using 1.8, but had some problems downloading it and I tried 1.9.1.13 instead. To my surprise, this one works fine. It uses the engine from Firefox 3 so I’m happy now.
The second issue is inability to control all the aspects of printing. One of the problems is that selecting the “only the selected frame” option still prints the whole page. I have a many pages with HTML frames and currently I advise users to open the desired frame in a new window before printing it out. If anyone knows how to solve this… please say so.
Next issue is getting landscape print to work. There’s a TODO in Kirix code, but I managed to fix it with just a few lines a code. I understand that this might be an ugly hack, but I don’t really care that much as long as it works. As I understand, my code doesn’t actually switch to landscape print, but rather sets a wider page for regular portrait print. Anyway, there the code. Just apply this to OnPageSetup function:
Finally, Firefox prints the default footer and header that includes page URL, which I want to avoid. In fact, I removed everything except the page number. I did not bother to look into coding this, as it seemed too much work. Instead I ran about:config in my regular Firefox installation and searched to print related settings. It was rather easy to find header and footer. Luckily, you can change these from code:
I have a MySQL table with 16 million records using MyISAM format. I tried to converting it to fixed as opposed to dynamic format hoping to improve performance. However, it killed my RAM and CPU. Here’s the table structure:
CREATE TABLE IF NOT EXISTS `poeni` ( `userid` int(11) NOT NULL, `naziv_igre` varchar(11) NOT NULL, `datum` date NOT NULL, `poena` int(11) default NULL, `podaci` varchar(65) default NULL, `zapoceto` datetime default NULL, `zavrseno` datetime default NULL, PRIMARY KEY (`userid`,`datum`,`naziv_igre`), KEY `zapoceto` (`zapoceto`), KEY `datum` (`datum`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
I created a new table named ‘poenifixed’ using ROW_FORMAT=FIXED option and copied the data using INSERT INTO … SELECT * FROM…. It took about 24 minutes. Then I created indexes on the new table. It took 35 minutes and 23 minutes respectively. While creating index MySQL also created temporary files as big as the table file. I have no clue why.
As expected, a new table has much bigger filesize, 4GB vs 1GB for dynamic. I could live with that though. So, I put the new table in production and 20 minutes later all the RAM on machine was consumed :(
I suspected something else is wrong, but couldn’t find anything. So I rebooted Linux, and it started working nice again, although I did not see any speed improvement. About half an hour later, the system load when sky-high, over 90. I took me a few minutes just to log into the box remotely. Now I switched back to dynamic table, inserted the records that where inserted by the users in the meantime and let it run. Everything works as before.
I really don’t understand why would a fixed table format require more CPU power or RAM. It should have been less in theory.
I have a heavy-used website powered by LAMP stack (CentOS Linux, Apache 2, MySQL and PHP). It started on a shared hosting so I had to use MySQL. Year and a half later, I switched shared, virtual hosting and not run it on a dedicated server. I decided to try Firebird to see how it performs and also how it compares to MySQL in RAM usage, disk usage, etc.
The software
The system is CentOS 5.5 64bit with default LAMP stack. I installed Firebird 2.5. RC3 from the .rpm package on Firebird website. Surprisingly, it does not require any additional rpm package :)
Converting the database
As far as I can tell, there are no tools to do this automatically. I created Firebird database and tables by hand, slightly editing the schema dump from phpMyAdmin. This was easy. Loading the data seemed a problem because default mysqldump places multiple VALUES clasuses in INSERT statements. I used a Postgres tool mysql2pgsql to convert the file to a more usable form:
Next problem was that ” and ’ are escaped with backslash .
With Firebird ” does not need escaping and ’ is escaped with another ’, becomes ”. A simple sed command to fix this:
cat postgres.sql | sed s1\\\\\"11g | sed s1\\\\\'1\'\'1g > firebird.sql
A few more manual edits were needed to remove the CREATE TABLE and similar stuff, because I only needed data. After that I added “commit;” to the end of the script and ran it via isql:
and that worked fine. At least for the system date and time. After this, I rebooted the system to make sure everything will be alright afterward. However, PHP’s date() now showed 4 hours more instead of less. MySQL was ok. I got really confused by this, and I digged into /etc/php.ini and changed the date.timezone setting to:
By screencast I don’t mean slideshow, but real-time recording of screen. I used the following software:
- recordmydesktop - mencoder
Recordmydesktop is great program, it only has one subtle bug: it does not allow X or Y coordinate to be zero, so I had to move all the windows 1 pixel to the right. No big deal. I recorded on a 1024x768 area using 1680x1050 screen, so there was plenty of space off-camera that I could use the stage content and record everything in a single go.
I used mencoder to convert the video from Ogg/Theora to other formats. Although I prefer Ogg, many hardware DVD players do not support it (in fact, it’s hard to find one that does).
I had problems with sound setup, although everything was at max in KMix, it was not loud enough. I have same problems using Skype, so this is some problem with my computer, not the software. Luckily, mencoder can also manipulate volume, so I increased it during conversion. I used a line like this one to invoke mencoder:
“If you encounter the problem please could you report
it in this forum. We need a bit of information to help us, including
your Twitter username and the browser you are using.”
I call that BS. As if they don’t have that information available
already. My twitter username is sent in the request that fails.
Browser sends its UserAgent. Just log it, damn it!
Of course, to report the problem you have to log in to forum, and to
log in, you have to create another account. TweetMeme should be a
modern web 2.0 website, yet for their forums they use the
“username/password” concept from stone age. As if OpenID and
all the related technologies do not exists.
Now, I hope all the websites in the world read this and start using
some Twitter integration tools that actually work.
I have a website with dark background and light colored text and
needed some WYSIWYG editor for on of the forms. Only special
requirement is support for smileys. I considered:
CKEditor
TinyMCE
openwysiwig
Xinha
wmd
wmd is not WYSIWYG, so that one was off. openwysiwig was easiest to
configure, but same as Xinha it did not have simleys. So, I was left
with “power” ones.
First I tried TinyMCE. It was rather easy to configure to be used with
dark background, but it’s smileys have a few-pixel white border around
them and it looks really ugly. I guess I could have created my own
smileys or edited those provided, but I just wasn’t ready to invest
that kind of effort.
So, I tried with CKEditor. Setting it up makes me never want to create
a dark website anymore :(
There are multiple problems that you need to tackle:
1. In contents.css, set something like this:
body { color: white; background-color: black; }
2. in config.js you could set: config.uiColor = ‘#000’; but then the dialogs (special character, smiley, link editor, etc.) will look really ugly, and text of labels would not be readable (black text on black background). To work around this, I left the default uiColor (to make sure dialogs are ok) and added a style that .uiColor setup would create (determined by Firebug). After your ckeditor declaration in HTML file, add this:
I used #999 for dialog tabs, but this is really not needed (it looks nice though)
3. the final obstacle was color of links. If you have A tag present in your textarea it will be rendered as blue, which has almost no contrast against black. To change this, I added the following to my CSS file:
.myckeditor a { color: yellow; }
and forced CKEditor to use it via the following setting in config.js
config.bodyClass = 'myckeditor';
This made it work… well, sort of. If link was already present in works in all browsers. But if you add a link using the “link” button, it would work properly in IE and Opera, but not Firefox (tested with Firefox 3.0). Interesting enough, debugging it with Firebug shows the correct CSS color being used, although it is not shown on screen. The trick is to add !important to CSS:
.myckeditor a { color: yellow !important; }
Another tip for the end: CKEditor has a context menu which replaces the default menu so you cannot click some text inside the editor control and use “Inspect element” opcion of Firebug. To work around this, add the following to your config.js:
config.browserContextMenuOnCtrl = true;
now, you can invoke the default context menu by holding down Ctrl key while pressing the right mouse button.
Using PHP’s serialize function to serialize and array or object where some element is a string with UTF8 data creates the serialized string properly. However, unserialize function fails to unpack that data. I ran into this when setting session flashdata from my CodeIgniter application. The solution I find to work (not sure if it’s perfect though) is to use mb_unserialize function (found in comments of PHP manual).
To use this with CodeIgniter’s session, just change Session’s _unserialize($data) function to use mb_unserialize instead of PHP’s original function. Grrr, I lost hours debugging this and finding a solution :(
Update: the problem became evident only because I used a wrong connection charset. Still I don’t like PHP returning an empty string when it cannot convert one character. I like the way some other programming languages are doing by placing a question mark (?) instead.
I have a laser printer installed on a Linux box which is working from
Linux correctly. I can also print from other Linux machines in the
network via CUPS. One of the machines in the network runs Windows. I
shared the printer via Samba, so that Windows can “see” it via
standard Windows networking. Windows has driver for this printer
installed, but CUPS won’t allow it to print. The trick is to configure
CUPS to allow “raw” data to be sent directly to printer. To do this,
edit the file /etc/cups/mime.convs and uncomment this line (it’s near
the end of file):
I cannot reach some of my websites for days now (from Europe):
traceroute to guacosoft.com (67.225.154.235), 30 hops max, 38 byte packets
1 192.168.0.44 (192.168.0.44) 1.558 ms 1.578 ms 1.398 ms
2 WIRELESS-CORE.panonnet.net (82.208.248.250) 4.029 ms 3.961 ms 3.912 ms
3 CORE-WIRELESS.panonnet.net (82.208.248.249) 4.229 ms 4.289 ms 4.095 ms
4 213.163.35.241 (213.163.35.241) 13.144 ms 7.760 ms 14.524 ms
5 213.163.35.249 (213.163.35.249) 19.031 ms 9.630 ms 14.701 ms
6 xe-4-0-0.bix-p2.invitel.net (213.163.54.218) 73.666 ms 13.240 ms 13.884 ms
7 ge-7-0-0.bix-c1.invitel.net (213.163.54.157) 10.110 ms 16.060 ms 12.155 ms
8 * Port-c2.401.ar2.FRA4.gblx.net (67.17.157.249) 39.496 ms 28.159 ms
9 GIGLINX.TenGigabitEthernet3-1.ar5.CHI2.gblx.net (208.49.135.162) 131.646 ms 147.448 ms 142.747 ms
10 lw-dc2-core3-te9-1.rtr.liquidweb.com (209.59.157.224) 136.624 ms 147.189 ms 203.293 ms
11 lw-dc2-sec2-dist3-po1.rtr.liquidweb.com (209.59.157.222) 142.022 ms 142.622 ms 141.918 ms
12 * * *
...
29 * * *
30 * * *
There’s a bug introduced between PHP 5.2.1 and 5.2.2 that affects
handling of Firebird blobs on 64bit machines. Having moved some of my
servers to 64bit Slackware (Slamd64 to be more precise) I run into
this problem.
Unless you want to recompile the whole PHP to a newer version with the
fix (5.3 as I understand, although did not test), you can patch the
sources: Just open ibase_blobs.c file and modify this function:
_php_ibase_quad_to_string
char *result = (char *) emalloc(BLOB_ID_LEN+1);
/* shortcut for most common case */
if (sizeof(ISC_QUAD) == sizeof(ISC_UINT64)) {
sprintf(result, "0x%0*" LL_MASK "x", 16, *(ISC_UINT64*)(void *) &qd);
} else {
ISC_UINT64 res = ((ISC_UINT64) qd.gds_quad_high;
sprintf(result, "0x%0*" LL_MASK "x", 16, res);
}
result[BLOB_ID_LEN] = '\0';
return result;
Rebuild the interbase.so, copy to extension directory, restart Apache and you’re done.
What to do with average developers that do bad things without even
thinking about it?
Short answer: do NOT hire them.
Being an ISV owner I have a challenge of hiring developers to help me.
Most of them do help, but if their commitment to the development and
the company is not real, they will produce many errors. They simply do
not care: “just close the tracker item and go home” is the policy.
What prompted me to write this is anger I feel, after users reported a
huge bug I believed was fixed ages ago. In fact, it was fixed 17
months ago. I just found my commit (hash
2f51bc152d03e6efbfcb563c46519cc5872d971d in our Git tree). However,
our employee had a small fix on that file (changing a single line) a
few days later and he got a merge conflict.
Instead of going in and applying his change to my version (which changed some 50+ lines) he
decided to simply rewrite it with his own. He could, of course, ask
any other developer to do it, but I guess that was too much work. It’s
easiest to screw things up, and not close your tracker item.
Anyway, he left the company some time ago, so it does not even make
sense to tell him about this. Somehow, I feel it’s my own fault, maybe
I did not provide enough motivation? Experiences like this assure me
in thinking that you should never hire mediocre developers. Well,
unless it is not your company and you can leave tomorrow, careless
about any wreckage you leave behind you. Nobody is going to blame you
anyway.
I
have been using it since 2002. It’s rock-solid, small-footprint,
lean and mean database. And it’s completely free. No dual-licensing
crap like MySQL, no crippleware like Microsoft or Oracle Express
editions.
Not mention 2MB embedded engine with x-copy deployment (just copy a
few DLLs alongside your EXE and you’re good to go). And, without any
changes to the applications, it scales to 10 GB databases (largest I
tried myself, reportedly, there are much larger ones out there).
Imagine a world where DBMS download is a few megabytes and install is
a few seconds…
Well, do not dream, try Firebird and see it for yourself. Once you get
used to that, other DBMS will look like bloatware.
When I read a new software announcement like this:
“According to KDE’s bug-tracking system, 7293 bugs have been fixed and
1433 new feature requests were implemented.”
my brain actually receives this:
“According to KDE users’ complaint system, 1433 new bugs were
introduced and 7293 features that had to work in previous version are
now actually working.”
KDE is just the example, don’t get me wrong. I’m using KDE as my main
DE and I like it a lot.
Anyone using Google Analytics, AdSense and even Google search knows
there is some kind of fuzzy logic applied to the counting process,
especially when sum of all values is not quite mathematically correct.
I never wondered much about it because Google runs a lot of data
through their system and it could all just be the cloud effect, or
even really AI fuzzy logic.
Until, today I tried to access YouTube with Firefox 2, and I got this
interesting message. Admitedly, it is a nice way to promote Google
Chrome browser, but it also shows that Google has even trouble
counting to 5. For those of you not looking at the screenshot: the
text says “here are 5 ways to leave your browser”, and shows only 4
browsers listed underneath ;)
Well, maybe this is really a sign of future world domination. The
original Pentium I processor also had problem with math, and Intel is
#1 in that area today.
Facebook
is introducing new layer of privileges for Facebook applications.
For getting someone’s e-mail address. If find this to be
useful, but it doesn’t look like they prepared this well.
At first all the links in notification e-mail were offline.
I guess all application developers went in to read about the
changes and servers couldn’t handle the load. Still, main
FB service was operational, so it makes one wonder why didn’t
they use that powerful infrastructure, at least for static pages
like documentation.
I finally managed to read about what needs to be done, and
I set up the domain. Of course, there is not example given in
their docs, so I assume it is domain like mydomain.com. Anyway,
I just received e-mail saying that “We have determined from
our logs that you are currently requesting email access, but have
not yet configured your email domain”. WTF?
I got this photo from one of my users. They created a nice box, placed a big CRT monitor inside, turned facing up, and added two controllers. Njam for the whole family.
There is 100000 ways to do anything on Linux. Of those, only 3 ways are doable by mere mortals, of which only 2 ways fit what you might understand, and only 1 way is the way YOU WANT to do it.
Linux is really hard for people who don’t have time (or a Linux-guru friend to help them) to find those 2 ways. Linux is easy for those who find their true path :D
I took this photo during my vacation on Corfu last summer. Of course,
it reminded me of Firebird JDBC driver, which is named Jaybird. Maybe
Roman (the main developer) was on the yacht, but I didn’t take the
time to check it out. Just kidding.
I went to facebook today and have seen an interesting, “get
rated” ad on the right-hand size. I followed the link, and got this
(screenshot attached). Interesting, eh? “You must use the latest
version of Firefox, and 3.5 is not enough :)” LOL. Looks like they
don't know that 3.5 is already out. I assume that check is something like:
if (version != 2.0)
I guess people at get-rated.com really know how to spend their marketing budget. But without functional product, the money is really thrown out of the window.
I’m moving one of my websites to a different server, and part of it is moving a MySQL database. It has different international users and a lot of data in UTF-8 character set which does not fit into default ISO 8859-1 space. Using phpMyAdmin (no other way on old host) I backed up the entire database into .sql file encoded with UTF8, but when I imported it from the command line using:
mysql -p mydatabase
however, all the non-ISO8859_1 characters got busted and don’t display correctly. Solution is to supply the connection character set, so all data is transferred as UTF-8:
mysql -p --default_character_set utf8 mydatabase < dump.sql
I really surprises me that Facebook, which is supposed to be full of smart developers, can allow themselves to have some simple things done wrong. They never got the back button right. While browsing, all the links open in same window, so when you are in the middle of the very long “wall” page and click on some link, there’s no easy way to get back there - you need to scroll the whole page. So, you need to remember to open all links in new tab or window. The thing that prompted me to write this post is, however, a more serious issue. I was in a middle of a long “wall” page and clicked a link to join a group. Quite a common action, but it uses javascript so you cannot “open in a new tab”. I joined the group, and group page opened. I read a little about it (on group’s main page, without navigating anywhere) and clicked Back to go back to my “wall” What a mistake that was: FB completely stuck my browser, switching back and forth between 2 (or is it 3) pages. I could not press the Stop button (I could, but it does not stop it), nor select another URL from the toolbar. It simply entered an endless loop, and I had to kill Firefox to make it stop. Looks like all the story about FB developers doing it “cool” and “smart” is not really true once you scratch underneath the surface.
Ever since I installed Firefox 3.5 I felt it was a little bit more sluggish, bloated and slow compared to previous versions, but I liked some of the new features.
But today, I just had enough. To state it plainly: Firefox 3.5 IS SLOW!
I installed Firefox 2.0 and it flies. It must be like 3 times faster and 2 time less resource intensive. One of the things I also disliked about 3.5 is that sometimes when I’m not doing anything, it would start to do “something” that requires hard disk, so my disk would get really busy.
I hope Firefox developers get their stuff together and makes the browser better, not just more feature-full. Some of the features in 3.5 are really strange. For example, the + button to open new tab. There has been a toolbar button to open a new tab since forever (I always add it after installing). Instead of simply making that button shown by default, they apparently decided to do copycat job of some other browser’s feature. That was very cheap move, esp. since I find the toolbar much more useful because it is always at the same place on the screen and I don’t have to search for it.
Competition is moving forward (Chrome, Opera, …) and it seems Firefox is losing the direction. It there wasn’t for great plugins, it would lose market share quickly.
Update: Since Firefox 7, things have been fixed. Firefox 14 I'm currently using is the fastest browser on the net.
Today I started testing Yii framework. I have previous experience with CodeIgniter so this will be a nice comparison.
I got a hold on to basic concepts, and first thing that made me stuck for a while was doing the proper URL redirection to create SEO links instead of index.php?r=controller/action. I set up .htaccess without much trouble, but It turned out that default applicaiton generated by Yii is missing this line in website/protected/config/main.php:
I got this idea about a website with online whiteboard capability. I
went googling to find out if there is something good out there before
reinventing the wheel. Here are some experiences:
Skribls looks very promising, but it does not deliver. It seems to have some bugs: I cannot change the color when drawing lines and I don’t see any tool to erase. Also, I don’t see any way to quickly clear the board. Maybe the problem is in browser support, I don’t know. I’m using Firefox 3.5 which is really as standard as you can get today.
Main drawback is that it requires Java, and if you don’t have it installed or enabled, it would just sit there with it’s progress bar running. I thought something was broken with their website after nothing go loaded in 15 minutes. It turns out Java was disabled in my browser. They could put a simple detection with “please enable Java” message. Functionality isn’t great either. Interface is well thought off, but many things just don’t work right. Drawing a free-hand line is not as nearly as smooth as in Skribl, so what you really get is a lot of short straight lines and corners. One big problem is also that their code runs my CPU at 100% all the time - even when focus is not on the browser window. Tool for erasing is easily accessible, but it does not work well - trying to erase a single straight line can take quite an effort.
So far, a clear winner. It uses Flash, and works very well. Freehand drawing is pretty good, adding text is as simple as click&type. Drawing shapes, adding images and files and integrated chat. What more could one wish for. Also, the price for the features I need (i.e. free) is hard to beat. I only used it a couple of minutes, but if we assume there are no serious bugs hidden in it - this looks like The Real Thing(tm).
Please add a comment if you know of another good online whiteboard (esp. if it does not use Flash but DHTML - because not all computers have flash installed).
My wife has got this Lenovo S10 IdeaPad netbook and I sometimes
“borrow” it, esp. in the evenings when I turn off my computer. It’s so
much easier to keep this small computer on the lap when lying in the
bed. Is got great wifi, much better than my HP530 notebook, so having
Internet access is great.
I really don’t want and don’t like to boot into Windows, so I just
select to go into that minimal Linux environment available at boot
time. It’s great way to browse the web safely. Lenovo has a nice
Firefox ripoff named Splashtop Browser. One of the mail things I’m
missing in it, is the options menu. For example, you cannot change the
homepage, so whenever browser is started, it goes to Lenovo’s website.
I guess they like to have stats - how many copies of Splashtop Browser
get started each day.
Another thing Lenovo did, is made sure Firefox makes no money from Google when using Lenovo netbooks. Money goes to Lenovo instead. Average user won’t even notice it, but if you use the browser’s search box in top-right corner, you can clearly see that search is “powered by google” and plugs into AdSense directly. Now, I don’t mind where the money goes, but custom AdSense linked search lacks important features that are otherwise available. Most important being: “image” search. You simply cannot switch to search for images, you need to go to www.google.com yourself. That sux Lenovo!
Firefox does this much better: they made a deal with Google, so when you search from Firefox, all is ok, you get the full featured interface. On the other hand, it seems that Lenovo did not want to make deals with Google (or couldn’t?), so they just opened an AdSense account and linked that into the browser. Who knows, maybe even Lenovo is unaware of this and some of their developers is getting hoards of money. Now, these are the issues I’d like to ask some Lenovo representative about if I even get a chance to have an interview once. But don’t worry Lenovo, it’s not like that going to happen, ever.
Another interesting thing is battery meter. Just a few minutes ago I
got a warning message saying something like: “battery running low, you
have one minute left”. About 3 seconds later, system turned off. Nice
estimation Lenovo :)
If I was typing a lengthy e-mail these 3 seconds will probably not be
enough to scroll down and save it. So, once you see the battery going
red, get a hold on a power supply quickly.
One more thing I don’t like about this minimal Linux environment is that integrated touchpad does not support advanced actions: drag&drop and scrolling (when moving a finger along the right edge). Those do work in Windows, so I assume Lenovo forgot to configure something. As there is no access to terminal, there’s really no way to see “under the hood” or try to fix it.
I wanted to install a simple PHP wiki for my website, so I can create
shared content with two of my friend. We are all dislocated, so it has
to be on the Internet. I have a hosted website at www.guacosoft.com,
so I decided to put it there in a subdirectory. I needed something
really simple, using plain text files or a MySQL database. I had some
previous experience with DokuWiki, as I set it up for
www.flamerobin.org, so first I tried that.
DokuWiki uses textual files to store content. There’s always a
potential problem with setting up filesystem privileges in such case,
especially when you need to move the site. But, that’s not such a big
deal. One of the things I was also scared of is that someone might
find an exploit and can ruin the rest of guacosoft.com website, which
would be really bad. But still, DokuWiki is great Wiki software, very
simple to use, and markup is really clean and straight forward.
Unfortunately, the latest version unpacks way to many files from the
archive. Try to upload these via FTP took ages, and I finally gave up.
Maybe it’s cool when you run your own server, but on shared hosting
website it’s really not usable. Maybe I should have gone in and copied
directories one by one, but I was too lazy for that.
So I started searching the web. One of the most promising seemed to be
phpwiki. Install was small, upload to the server when fine, but then
the troubles begun. PHPWiki is simply not good if you don’t have your
own server. It wants to do some crazy things like writing to /tmp. I
also tried to set up MySQL as the storage, but for some reason this
did not work. In the end, all I managed to do is get 500 HTTP errors
(internal server error) from my web server. So, I gave up on it.
Next on the list were MediaWiki and TikiWiki. Looking at the feature
list this seemed too bloated for my needs. If you run a huge and
complex site, that is probably the right choice. But for 3 people
cooperating on internal project… overkill.
Looking at the “list of wiki software” on Wikipedia, I started trying
them all one-by-one…
NotePub is a great idea, but it seems their servers don’t scale to
number of users. Website’s response is way to slow. Too bad, as this
seemed like the simplest way to do it. Nothing to install on my
server, just log in and edit stuff.
TigerWiki is dead, forked into multiple other projects. Most of those
lack the same thing the original lacks - support for multiple users. I
really don’t see a point in having a wiki for a single person, because
wikis are about collaborative editing. PumaWiki seems promising
though, kakwiki has added users, but it’s still at development at this
stage. I really did not want to be someone’s beta tester in this case.
I needed something that Works(tm).
And now we come to WakkaWiki, which is not longer developed or
maintain, but there are number of forks. And here we find our winner:
WikkaWiki
Install was simple and painless. Once files are copied, you open the
page in the browser and wizard leads your through the settings. At the
end, all I had to do is to allow a single config file to be written by
the server and that’s it. It uses MySQL for storage and behaves like
it should - i.e. there’s an option to prefix all table names with
wikka_ or whatever you prefer. I’ll see how it shows during usage, but
currently I can highly recommend it to anyone.
I’ve been using Yahoo! web mail since 1999 or something around that.
There was a time when it was slow and bloated and Internet connections
were slow. At that time, first browsers that allowed to block images
were a bless. Later, when Firefox came out and we were able to “block
images from xyz site” it was really good. They soon replaced those
with flash ads, but those were even easier to circumvent, either using
flashblock or not installing flash at all.
However, ads are not what’s bugging me. It’s the stupid new “Chat &
Mobile text” box on the left side. I don’t want to chat, I want to
read e-mail. Google Mail has a similar feature for some time, and it
was driving me mad because it would change the size of the box at some
point and move rest of the page below it, making me miss some clicks.
Anyway, Google was smart enough to remove it (or allow us to remove
it, I can’t remember).
But Yahoo! seems to be a different story. The box just stays there,
presumably drawing my bandwidth with some AJAXy calls. I have to press
Cancel for it to stop. EACH TIME. This is really annoying. I search
the options, and there doesn’t seem to be any way to turn it off.
I understand that some people would like to chat while they are
reading e-mail, but I’m not one of them. Why would I want anyone to
know I’m online while I’m reading the e-mail. Can’t I just read my
e-mail in peace and quiet?
BTW, Facebook is plagued with a similar problem. As soon as you are
logged in to read other people’s updates, someone of your “friends”
might jump in to chat with you. So, the only way to work around this
issue is to ignore them? How nice is that?
Just let me be non-existent until I’m ready for the world…
After spending endless hours days trying to get some
webdesign at my latest website to work correctly on most browsers using
CSS, I finally gave up and decided to use tables for a small part of it.
You would suspect that the usual suspect, IE6, is the one to blame, but
no. It was Mozilla Firefox 2.x. I couldn’t even find
any CSS that would display the way I wanted, even if it
would break some other browser. All others would work without a glitch:
Firefox 3, IE6, IE7, IE8, Safari, Chrome, Konqueror.
You might say that I should just tell Firefox users to upgrade to
Firefox 3. I’d love to do that. However, statistics show that
about 5% of visitors are using Firefox 2, and I simply did not want
to lose them. So, tables are back until everybody switches to Firefox
3 or above, and then I’ll probably remove them and go back to
clean CSS.
Earlier I wrote about an interesting article regarding takeover of expiring domains. Recently I had a first-hand experience myself:
For about two years we run the website www.firebirdfaq.org. It has
become pretty successful if you consider the niche market it covers,
that being the users of Firebird DBMS. Ever since the start in 2007. I
wanted to somehow get a hold of the .com variant of the domain. Just
to make sure that people who mistype the URL come to the right place.
At the time it was owned by someone in Germany, and they did not seem
to use it much (no website, only e-mail apparently). In fact, it was
to expire in August 2007, so I spent $19.99 or something like that on
GoDaddy to grab it. To my misfortune, the owner extended the
registration, and I canceled monitoring on GoDaddy. I completely
forgot about it until a few weeks ago.
August 2009. came and domain registration was not extended. I was
completely unaware of this, but I got an e-mail from
initrustbestdomains.org saying that domain is soon to be deleted and
enter the market. They offered my to send a bid for the domain. My
guess was that these guys already have a pick on it, so I don’t stand
much chance if I go alone. I even considered placing an offer for $30,
but I though that was a bit too low. So I decided to do give up on it.
And here it gets interesting:
At the moment when domain was deleted and returned to the “pool” I got
this e-mail:
We are selling the domain name firebirdfaq.com. Since you own firebirdfaq.org if you would also like the more desirable .com we are making it available. The one time cost is $99.97. That includes a year of registration and transfer of ownership to you. To purchase or to learn more go to:
hxxp://www.buyyourdotcom.com/check…etc.
If you pass on this opportunity someone else could purchase this domain and it may not be available again.
Cool? Not!
Instead of giving them a hundred, I went to GoDaddy and registered the
domain for $9.99. ;)
Of course, all this was a little bit of gambling on my side and I
could have lost the domain, but it wasn’t that much important to me.
YMMW.
Is it just me, or sf.net has decided to take some radical steps:
milanb@kiklop:~/devel/flamerobin-trunk$ svn up svn: This client is too old to work with working copy 'flamerobin'; please get a newer Subversion client
milanb@kiklop:~/devel/flamerobin-trunk$ svn --version svn, version 1.4.6 (r28521) compiled Feb 1 2008, 17:17:53
I find it funny that you cannot use a less-than-2-years-old client to access the server. I don’t blame sf.net much though, I just hate people who break backward compatibility (SVN team in this case).
I really hate companies that simply don’t care about backward compatibilty. Yahoo! is phasing out it’s Messenger while completely disregarding the Linux users. It even offers me to download the new version and then gives .exe file. Not that Linux port of Yahoo! Messenger was really good, I’m using Kopete and Gaim/Pidgin. But getting constant messages that “You are using an older version of Yahoo! Messenger that is no longer supported.” is a major PITA. Ok, I got it the first time, but it keeps nagging.
This is getting to the point that I really don’t care anymore. I guess I’ll switch to google talk or whatever. Maybe the new messenger is sooo much better, and it will attract more new users they they lose.
I’m currently using Slamd64 which has this built in, so I have yet to try it. I hope it’s of good quality and Pat decides to include it in official package
Few years ago I wanted to take
over an existing domain that was to expire soon. I wasn’t looking
much for information about the process, but this would have helped me a
lot (if the owner did not extend it, that is):
I recently found myself in the position of wanting to
register a domain which was owned by someone else. The domain was set to
expire in a week, and I figured there was a decent chance that the person
who owned it wouldn’t be renewing it. Upon consulting the WhoIs registry
on the current owner, I discovered the guy was a bit of a domain shark
and didn’t seem to be around anymore.
So I placed a backorder
through GoDaddy for $18.95 thinking that was all I needed to do.
During the week that followed, I learned a lot about the domain expiration process. Two and a half months and $369 later, I am the proud owner of a shiny new domain. A really really good one.
This article will explain the domain expiration process and what you need to do in order to use it to your advantage. How a domain expires
Contrary to popular belief, domains do not expire when they say they do. If the owner of a domain does not renew by the expiration date of the domain, the domain goes into “expired” status. For 40 days, the domain is in a grace period where all services are shut off, but the domain owner may still renew the domain for a standard renewal fee. If a domain enters this period, it is a good first indicator that it may not be renewed, but since the owner can re-register without penalty, it can also just be a sign of laziness or procrastination.
After 40 days are up, the domain’s status changes to “redemption period”. During this phase, all WhoIs information begins disappearing, and more importantly, it now costs the owner an additional fee to re-activate and re-register the domain. The fee is currently around $100, depending on your registrar. When a domain enters its redemption period, it’s a good bet the owner has decided not to renew.
Finally, after the redemption period, the domain’s status will change to “locked” as it enters the deletion phase. The deletion phase is 5 days long, and on the last day between 11am and 2pm Pacific time, the name will officially drop from the ICANN database and will be available for registration by anybody.
The entire process ends exactly 75 days after the listed expiration date. For an even more detailed explanation, read the article Inside a Drop Catcher’s War Room. Landing your domain
So if domains are available to the general public 75 days after they expire, how do you know your GoDaddy backorder isn’t one of many other backorders from other people using other services? The answer is, you don’t.
And thus begins the cloak-and-dagger game of “getting in on The Drop”. “The Drop” is the unpredictable three hour period of time in which the domain is deleted from VeriSign’s database and released back into the ecosystem.
I briefly thought about trying to beat GoDaddy to the punch by manually registering my domain during the drop process, but I quickly found out that there are no fewer than three major services which specialize in pounding away on VeriSign’s servers during the drop period. With their considerable resources and my measly Powerbook, there was no way I could compete on their level.
So I decided to enlist the services of all three major domain snatching firms in hopes that a) one would grab my domain for me, and b) no one else would be competing against me.
The three services — Snapnames.com, Enom.com, and Pool.com — all operate in a similar manner. They use a network of registrars to hit the Verisign servers at frequent intervals (but not too frequent to get banned) and snatch as many requested names as possible. If you don’t get your name, you don’t pay. But that’s where the three services begin to differ. Snapnames.com
Snapnames.com (the exclusive partner of Network Solutions) charges you $60 for your domain unless there are multiple suitors, at which point there is an open bid auction between suitors. Seems fair enough. Snapnames is a bit of a newcomer to the game, but with their Network Solutions affiliation, they are said to be improving their success rates. Enom.com
Not wanting to chance it with only one company, I also enlisted Enom to snatch my domain for me. Enom had reportedly been improving their “Club Drop” service for a year or two and it was now considered one of the top three. Their fee was only $30 and they are based in my ‘hood (Seattle), so I was hoping they would be the company to successfully “work The Drop” for me.
Here’s where it starts to get sketchy though.
Enom claims that the higher your bid is (beyond the $30), the more “resources” they will dedicate to grabbing the domain. What the hell? How am I supposed to judge that? Does that mean you’re using one server now and will use 30 servers if I bid $40? Or does it mean that you’re using 30 now and will use 35 if I bid $1000?
Not knowing exactly what to do, I attempted to bid a couple of hundred dollars during the last day, but Enom required me to send them a fax to become a “verified bidder”. Since I was at home that day and only dinosaurs still have fax machines, I was unable to increase my bid. Oh well, I thought, if someone else on Enom bids higher, at least I’ll be able to participate in the auction. Pool.com
Pool.com is the Scott Boras of domain name grabbing — the brilliant, yet conniving agent that players (domains) love and team owners (prospective domain buyers) hate. Pool plays off the power of the unknown in such a fiendishly clever way that you don’t know whether to hug them or kill them. Here’s how it works:
Pool is the #1 company around as far as number of servers and success rates go. You place your original bid for $60 and if Pool.com grabs your name for you, they send you an e-mail telling you they’ve been successful and that you’ve now entered “Phase 1″ of the two-phase auction system. This is the case whether or not you are the only bidder! Pool.com doesn’t even reveal how many bidders there are.
Then, in a Boras-like move of diabolical genius, Pool.com informs you that you have three days to place a new sealed bid. If the bid is either one of the top two bids or within 30% of the top bid, you move on to a one-day open bid auction (the “challenger” auction) for final control of the domain.
Grrrrreat.
So if I bid $100 and two people bid $140, I don’t even get to move on to the final auction! It’s all designed to get me to up my sealed bid… whether or not there are even any other bidders.
Note: One other thing I forgot to mention is that before the name dropped, I grabbed all .net, .org, and .info variants (all were available) in order to have more leverage over other buyers. The chase is on
Right on time, 75 days after the domain expired, I got an e-mail from Pool.com telling me they’d secured my domain for me. Great. Of the four sources I used, Pool.com was the one I least wanted to deal with. But true to their claims, they ended up being the best agent of The Drop and had just gotten me one step closer to my domain. They had A-Rod and I was the Texas Rangers.
Unlike the Texas Rangers, however, I realized I could be bidding against myself and entered a sealed bid of $302. I chose that number because it seemed sufficiently high but not so high that I’d feel foolish if I was the only bidder. I added the extra two dollars on the end just to edge out any other people potentially deciding on $300 as their number.
The next three days were particularly stressful. I had no idea where I stood, and throughout this entire process, I’d always had the sneaking suspicion that the people at these companies are on the lookout themselves for valuable domains. In other words, if someone all of a sudden bids $1000 on a domain, will a domain company decide to snatch it up themselves or “shill bid” against you on it?
Finally the e-mail from Pool arrived and informed me that I had moved onto the Challenger Auction. There was one other bidder and they had upped their bid to $312 in order to beat me. Not too bad, but I had no idea how high that person was willing to go. I had to decide on a top bid (a la eBay’s proxy bidding) and a strategy for when to place it.
True to form, Pool.com’s auction system squeezes even more money out of you by making sure the auction doesn’t end if there’s a bid in the last five minutes. In that case, the auction time keeps extending by five minutes until there are no more bids.
I could try one of two things: Bid high and bid early in an attempt to scare off the other guy, or lull the other guy to sleep by doing nothing until the last 6 minutes. I chose the second method since the ending time was 8am on a Saturday… a time when many people are not in front of computers. I set four alarms for 7:45am Saturday morning, woke up on time, and placed my bid for $500 when the countdown clock hit 6 minutes.
The system immediately auto-upped the current bid to $369 and I was the leader. Six nervous minutes, fifty browser refreshes, and a thousand heartbeats later, my opponent was nowhere to be found and the domain was mine… ready for immediate transfer to Dreamhost, my hosting company of choice.
I’m still not quite sure whether the person on the other end was real (although I assume they were), but the bottom line is that by playing every possible angle, I now have an extremely valuable domain in my possession for the reasonable sum of $369. Not valuable because I want to sell it or anything; just valuable because I want it.
Thank you Pool.com. I love/hate you. Lessons from The Drop
Hopefully this article helps you in your own quest for a domain that may be expiring. My best advice is that if your interest in a domain name is only lukewarm, go ahead and use a basic service like GoDaddy, but if you really don’t want to let one get away, you must enlist the services of the big three: Snapnames, Enom, and Pool. It’s anybody’s guess what the final price will be, but by getting all the best agents out there working for you, you ensure at least being in the game. UPDATE: Both Mason Cole of Snapnames and Chris Ambler of Enom have written in to clarify a few points which I’d like to post here –
* Snapnames has an exclusive partnership with Network Solutions which allows them first shot at any and all expiring domains that are currently held by Network Solutions. The domain I got was not held by Network Solutions but a great many are. If yours is, Snapnames is your best bet. You’ll still have to bid against any others who may be after the same domain, but the auction process at Snapnames is pretty fair and straightforward. If you are the only bidder, it will cost you a flat fee of $60. Not bad. * Snapnames is actually not technically a newcomer to the game, but their exclusive deal with Network Solutions is fairly new and it is that which has made them a powerhouse. * According to Chris at Enom, some less than savory registrars have been known to actually cut the initial 40 day grace period down manually with the intent of repossessing the domain for resale. While this is technically against ICANN guidelines, ICANN has a hard time enforcing its rules on registrars, so just beware when watching for a domain that it may enter the redemption period quicker than you expect. It’s rare, but it can happen, especially with a non-established registrar. This could shrink the 75-day window down to potentially 35 days, and it could also screw you out of your own domain should it expire on you. * Chris also confirmed my suspicion that manually trying to snag a domain during the drop is all but impossible if any professional drop catchers are going after it. Enom, Pool, and others have many orders of magnitude times the amount of resources that private citizens have so it’s not even worth trying unless you’re going after an uncontested domain. * There is a very sticky issue going on right now with regards to how names drop. Verisign proposed a Waiting List Service a little while ago that basically let you sign up on a waiting list for all expiring domains. It was a flat-rate, first-come-first-serve service where the fees were reasonable but Verisign controlled the whole thing. This would based eliminate The Drop entirely.
Companies filed lawsuits and the thing never happened. So basically,
registrars got proactive and amended their agreements so that
when your domain expires, they can repossess it themselves or
sell it as their own. This is what allows Network Solutions,
GoDaddy, Tucows, and others to repossess their own domains and
use their own services (like Snapnames) to auction them off. An
argument can be made that by eliminating the ICANN-mandated
redemption grace period, these companies are in violation of
their ICANN agreements, but thus far ICANN has been reluctant
to take action. It appears ICANN is generally very slow at
taking action with anything, so it looks like this sort of practice may
become a de-facto standard. The moral of the story is that you should
always look to see what registrar the domain you’re after is under and
see if they offer exclusive backorder rights to it. Network Solutions
does, GoDaddy does, Tucows is starting to, and others may follow suit.
I wonder why no windows manager or desktop environment implements this. I guess they are too busy copying Microsoft Windows to invent anything original. Anyway, the basic idea is that, instead of having a special Show Desktop button, we would always have the Desktop listed when switching windows or running applications.
This way you can easily go to Desktop by using keyboard, and not have a special shortcut for that (not to mention that possibility of shortcuts is not something most users are even aware of)
I got so frustrated writing blog entries here sometimes. I don’t get it: Blogger is used by (presumably) millions of users, yet the most basic things don’t work.
Example 1: Characters < and > do not get transformed to < and > when you switch between the HTML and Compose view. This means that and switching can be fatal to the contents. If you have a piece of C or C++ code with dozen #includes - it’s horror.
Example 2: Shortcuts for Italics and Bold just don’t work properly when you backspace. Here, I press Ctrl+b now. Then I delete that word. The indicatior (b letter at top of compose window) shows Bold is on. I press Ctrl+B to turn it off - indicator changes to off, but bold is actually ON. I start typing and bold letters appear.
I hope this reaches someone in Blogger team and they fix these trivial issues (I won’t even mind if they delete this post afterwards when it’s done).
I just installed Slamd64 version 12.2. I know that Slackware -current
is 64bit and Slackware 13.0 is out, but out-of-the-box 32bit compatibility
of Slamd64 is very tempting, so this is the first 64bit slackware I
installed.
Install went fine, and KDE is running in a matter of
seconds. Now, time to compile all the needed stuff for development.
Basically, all I need is Firebird, FlameRobin and PHP extension for
Firebird (i.e. InterBase).
1. Compiling Firebird
You could use the binaries on the website (which I learned later),
but AMD64 seemed suspicious (I run Intel Core2Duo CPU), so I decided to
compile. I downloaded the .tar.bz2 source package, unpacked it and
run:
./configure —prefix=/opt/firebird
Well, I first ran —prefix=/opt, but that turned out to be a bad
idea :(
Anyway, configure went fine, and then I ran
make -j2
because I have two cores. However, this is not supported as some steps
of build process are dependend on each other while that dependency is not
listed in the Makefile. Alex Peshkov says this should be fixed for
Firebird 3. So, make sure you only run
make
if you don’t want to see any errors. Once build is complete, run:
make dist
to create .tar.gz (and .rpm) packages. Just like official ones. Further
installation using this packages goes as usual (unpack + ./install.sh).
2. Compiling FlameRobin
This was the easiest step as everything works the same as on 32bit
Slackware. Compile wxWidgets first and then FlameRobin - all as usual.
3. Compiling PHP extension for Firebird (InterBase)
Using the PHP 5.2.8 source and steps on this link:
CI has a nice pagination class, which works nice, but has many
shortcomings. It has not been designed with much flexibility in mind,
so you might need to roll pagination on your own in the end. What are
the problems?
Let’s start with a minor one: when you have
4 pages, you get this:
first(1) prev(1) 2 3 last(4)
Same
link repeats twice. Similar when you navigate to 4th page in the same
example.
Then, there’s a problem that you cannot turn some
of the “components” off. For example, I don’t need PREV
and NEXT, just first/last and a few pages in the middle (number of those
is also NOT configurable, BTW). If you don’t set array members in
initialize function, it uses defaul values. Default values for start and
end tags are not what the docs say, and some defaults are next to useless
like
It would be much better if unset stuff defaults to
DO NOT DISPLAY.
The interface for pagination class was desined
by some narrow minded developer who only knows one way to do pagination.
For example, I do not like pure text links, but would like to use nice
rectangles. I managed to get something useful with SPANs and custom CSS
rules, however, I had to do some workarounds. For example, all the
links use simple and clean A tag without any interface to it. So, in
order to have links of different color than rest of the links on the
page, one has to add some CSS class to the outer element (create a span
that floats to left, for example), and then define CSS rule:
‘num_tag_open’ => ‘’,
‘num_tag_close’ => ‘’,
CSS:
.pagg a { color: #fcc }
Need to define all properties to make things look right on the screen is a real PITA.
Another problem is that it only supports determinate sets. I’d like to be able to have pagination without knowing the end record count. The reason for this is that many DBMS don’t perform well with SELECT COUNT(*) FROM table1 WHERE some_complex_query.
So, I just fetch initial 100-200 records and display them, showing the users that there is “more” with a link to “next” or “next 5 pages”. Of course, this would mean that there is no “last” link, which brings us back to the issue that this class only solves a narrow set of problems.
After completing a first real-world project with it, I get the impression that base stuff in CI is ok, but it hasn’t been tested enough in the real world situations. Many features seem to be designed more as a proof of concept than flexible framework designed for real world usage. Poor desing is also shown in Unit Testing which seems to be there just to fill the checkbox in the feature list, and also in ActiveRecord implementation which goes into sillyness of where_not, or_where and whatnot. As if writing select(‘column1’)->from(‘table1’)->where_in(‘id’=>array(10,20)) is much clearer or flexible than get_where(‘select column1 from table1 where id in (?)’, array(10,20)). IMHO, ActiveRecord should stay on the CRUD level.
I started using CodeIgniter some time ago, and here are the problems
I’m having:
nuking of $_GET does sound reasonable, but
it makes problems when you want to integrate with some other service like
RPX for example. I “fixed” this by writing a small php script
outside of framework to take the GET request and turn it into URL
acceptable by CI. (Update: apparently, this has been fixed in newer versions. I moved to Yii framework
since then, so I haven't checked)
The settings for Apache rewrite rule
you’ll find first is soo wrong. I mean, it is correct, but
it creates a hell of a lot of problems when you want to do something
outside of the box. Basically, you have to “allow” anything
outside of CI (even images, javascript and css) to be accessible.
The alternative snippet I found is much better (it basically says: if
it’s a real file, fetch it, if not, route through CI):
Here’s a nice script I use (I did not write it myself):
#!/bin/bash
#
# Check slackware-current
#
# Where to download from
# should script it so that the different sources can be listed and
# selected from the command line
SOURCE=”rsync://slackware.mirrors.tds.net/slackware/slackware64-current”
# Change as necessary
OPTIONS=”-avzP —delete —delete-after”
EXCLUDE=”—exclude=pasture —exclude=kdei \
—exclude=zipslack”
DEST=”/home/milanb/arhiva/install/distre/slackware/current64/download/”
case “$1” in
“-c” )
echo “Checking…”
/usr/bin/rsync $OPTIONS $EXCLUDE —dry-run $SOURCE $DEST
;;
“-d” )
echo “Downloading…”
/usr/bin/rsync $OPTIONS $EXCLUDE $SOURCE $DEST
;;
* )
echo “Usage: `basename $0` {-c|-d}”
echo -e “ -c : Check for updates”
echo -e “ -d : Download updates”
exit
;;
esac
######################################################
Setting up wireless on a public unrestricted hotspot has always
been mystery to me. I didn’t really need it often, and when I did I
did not have Internet access to google a way to do it. Well, today I was
with a friend so I used his laptop to find out how to set it up.
It’s
really simple once you do it. What’s important:
start up wireless card
scan for networks
pick a network and connect to it
Starting up a wireless card might require that you load a kernel
module manually. Some modules have option to turn on the LED
indicator:
# /sbin/modprobe iwl3945
Once you start it up, open the Wireless section in KDE Control Center,
and click “Activate” button.
Now, run /sbin/ifconfig
to see all the interfaces. You should see something like wlan0. Then, use
this interface name to scan the area for networks:
iwlist wlan0 scan
As a result, you’ll get each wireless network and it’s
ESSID. Let’s assume ESSID is MyHotSpot and connect to it:
iwconfig wlan0 essid MyHotSpot
In case you need to supply username and password, look into
wpa_supplicant and it’s config file (I haven’t tried this).
And start wpa_supplicant:
Once you’re done, use dhcpcd to get an IP address, default route,
and DNS server information:
dhcpcd wlan0
…and that’s it.
Update: there is a very nice and simple to use tool that
automates all this and wraps it into a GUI. It’s called wicd, and
you can find it in /extra in the newest Slackware, or fetch it from the
project page and compile it yourself (no special dependencies
needed):
Many times I wanted X11 forwarding to be as simple as
ssh -x host; run program.
Until today, that never worked for me. But today I was in the mood to
try to make it work somehow.
It turns out, it can be made to
work that way, and it’s super easy. The thing is that X11
forwarding via SSH is disabled by default (which is very reasonable
setting, BTW). To enable it, just open /etc/ssh/sshd_config on the
remote host (where you want to run the applications) and make sure
it contains the following lines (uncommented):
Printing from Firefox has been greatly improved in version 3, but
there are still some minor quicks. The most annoying one is that the
print dialog does not remember settings.
And some of the
settings have annoying defaults. Firefox developers should really
know that people are not just using web browser to browse the Internet
and occasionally print some web pages. Developers all over the world
are developing web applications for both Internet and intranet and
printing is very important.
The main problem I have, is that Header
and Footer settings are not remembered. So, for each page
I want to print, I have to go to that tab, set
all six fields to “—blank—” and
then print. Each
time I want to print anything.
I mean,
how hard could it be to save those settings somewhere in ~/.mozilla/firefox and
add a nice “Reset” button for people how change the settings
so much they get lost.
I have a home laptop and an office desktop computer. When I leave
office, everything is shut down, so there is no way to access the git
repository online. Since I didn’t want to drag my notebook to work
everyday, I got the idea to have a git repository on my USB memory stick.
One of the requirements was that it is a bare repository so
it does not take too much space. I had a lot of trouble figuring out
this one, and finally I got the right way when I understood
how git is meant to be
used.
I created a big file on my FAT filesystem,
and formatted in in ext2 with something like:
Then I mounted it and created a bare copy of my repos:
mount -o loop /mnt/stick/repos /mnt/repos
cd /mnt/repos
git clone /home/milanb/repos repos
When I go home, I repeat the mount on my laptop and pull the changes
into local development repository:
mount -o loop /mnt/stick/repos /mnt/repos
cd ~/devel/repos
git pull /mnt/repos/repos master
After I commit the changes, just push it back to stick:
git push /mnt/repos/repos
Now, the tricky part, when I go
back to the office, I was (stupid) to try to push the changes from
the stick to local repository. There are ways to make this work, but
quite awkward and error prone. Git is not meant to be used that way.
The rules are simple, if you do everything right:
- you
should never need to pull/fetch into bare repos - you should
never need to push into non-bare repos
So, what I really
needed to do is just to reverse the logic and pull changes from
stick into my local repository:
git pull /mnt/repos/repos master
It merges (unless there’s confict) and everything is fine.
To prevent from typing all those long paths, you can define aliases (remotes)
via git-remote command:
git remote add /mnt/repos/repos stick
And later just do these to pull and push:
git pull stick master
git push stick
All that time I used SVN and CVS just got that
centralized way of thinking into me. Finally I’m free ;)
Today I was looking for some tool to analyze my Git repository and show some nice statistics. Pie charts and bars would also be nice, but simple tables with stats also do the job. I’m used to seeing many good tools for the same task against CVS and SVN repositories, but Git is still young so my hopes weren’t high.
I used GitStat version 0.5. Now, I am an experienced developer and computer user, but the list of dependencies simply sucks. I mean, such simple tool to need all this is ridiculous:
* PHP 4.3.3 or later * GD 1.8.x or GD 2.15 or higher * Mysql 3.x or later * Perl, Perl-DBD-MySQL, Perl-DBI * Perl MIME:Lite Module (Lite.pm) copy to …/path_to_gitstat/gstat_pl/lib * GeSHi( Generic Syntax Highlighter ) * JpGraph 1.21 or JpGraph 2.2(for PHP5)
Both Perl and PHP? Copy stuff around manually? (why isn’t it in the package?)
Ok, I can understand MySQL for caching, but you still need to fetch changes from Git repos, so what’s the point? I bet it doesn’t do deltas and even if it does it probably does not handle rebase. Or maybe someone would prove me wrong. Wouldn’t something like SQLite be more appropriate for a tool like this?
Anyway, this seemed too much hassle and I really didn’t want the stats THAT bad, so I almost gave up… but then I noticed another tool, with a subtle difference in the name. It almost slipped because of that, so I hope authors of either of these two are going to invent some cool name for their project and create a distinction. Anyway, the other tool is named GitStats.
It’s a simple and dead-easy to use Python script. What can I say: It just simply works. The only dependency (beside obious Git and Python) is GNU Plot, which is installed by default on most Linux systems anyway.
It created the stats for my 1.5 years old, 1.5 million line of code repository in about 3 minutes. That was quite fine for me. No pie charts though, but maybe there will be some in future versions.
I found an interesting problem. In some of my PHP classes I needed
to ensure that destructor is called, even if user aborts the execution.
Well, I learned that user cannot actually abort it since clicking the
Stop button in your browser does not stop PHP, it keeps going until
either the script finishes (destructor gets called) or PHP timeout
is reached (destructor is not called).
I got worried about
this second case. After some time investigating, reading comments
in PHP online manual (that’s why it’s better to use online
than offline manual for PHP) I got to the following solution:
public function __construct($canvasWidth, $canvasHeight, $tickness)
{
...
register_shutdown_function(array(&$this, "shutdown"));
}
public function shutdown()
{
...do the stuff you would do in destructor
}
The only problem with this could be if your object gets destroyed
before script is complete. So, make sure you either implement some
safeguard code, or ensure object’s lifetime is ‘till the
end of script.
I have a kid that likes to play around my laptop while I work on it
and sometimes presses the power button. Default setup on Slackware 12.1
is that laptop starts the shutdown sequence right away. No need to mention
how frustrating can that be if you’re in middle of something.
I
decided to search for a way to prevent this from happening and have
my screen lock instead. I searched a little bit, and here’s a
nice way to do it.
To lock out KDE user session from the
command line, you can use this command:
Now, we need to make sure this gets called when power button is
pressed. Make sure that ‘button’ module of your kernel
is loaded (you can check with ‘lsmod’ and load it with
‘modprobe’ if needed), and then go and edit this
file:
/etc/acpi/acpi_handler.sh
Here’s what I have in it
now:
#!/bin/sh
# Default acpi script that takes an entry for all actions
IFS=${IFS}/
set $@
case "$1" in
button)
case "$2" in
power) /usr/bin/dcop --all-users --all-sessions kdesktop KScreensaverIface lock
;;
*) logger "ACPI action $2 is not defined"
;;
esac
;;
*)
logger "ACPI group $1 / action $2 is not defined"
;;
esac
It seemed easy. You just need: libsigc++ 2, gtkmm 2, libglademm 2.4.0, gconfmm 2.6.1 and PCRE. Some of those I already had, so I
only needed libglademm and gconfmm.
The first one installed
without problems: single tarball,
$ configure —prefix=/usr
$ make
# make install
Fine!
The other one (gconfmm)… well, it turns out you
need gconf for that, I did not
have it, so hop to the Gnome website.
Done? No, not yet, gconf requires ORBit2, so let go for that one
as well.
Now, after running configure, I started make. Since I have dual-core CPU I
used make -j2 but it seems I
found some bug in make (!?) since
it got stuck for 10+ minutes at one single point of compiling, with
both CPU cores at 100%. So, I killed it with Ctrl+C and run just make. That went fine and finished
in about 2 minutes.
By some magic, I managed to pick the
compatible versions, here they are:
regexxer-0.9
libglademm-2.6.5
ORBit2-2.13.3
GConf-2.21.90
gconfmm-2.24.0
I created Slackware .tgz packages for all this, download is
here:
Problem is that git-var does not work when you type ‘git var’,
but only when you type ‘git-var’. WinGit version is 0.2. So, the merge script bails
out with message.
To fix, edit:
c:\Program Files\Git\bin\git-merge
and change all ‘git var’ to ‘git-var’ and you’re done.
This is the first Web 2.0 application I would dare to call amazing.
In case you’ve been on the moon in the past few days, I’m
talking about www.stackoverflow.com
Idea
is probably nothing new, but the way it is done is brilliant. What is it
all about? Well, suppose you are a programmer like myself, and you run
into some minor problem you cannot manage to solve using
the 4 proven techniques of solving programmer’s problems:
look into manual
experiment
google
try to restart
I just made that up, but I like it :)
Anyway, if you don’t know how to solve it, the last resource is
to ask a friend or colleague who might know. But, with StackOverflow, you
get access to thousands programmers in the world, and some of them surely
know an answer to your problem. And, since website is live with questions
and answers all the time, you’ll get the answer really soon. A typical
use case for me:
have a problem
go to SO and post a question
while I wait for the answers, I browse the existing questions
and reply, vote, etc.
I check back every once in a while to find the answer and test it
right away in my code
b.e.a.u.t.i.f.u.l.
This works simply because, while waiting for an answer, I managed to
send replies to 5-10 other people. And once you get a critical mass,
it’s a ball that keeps rolling. Simply because you know you will get answers there.
And,
of course, there’s the whole rating, ranking and reputation (RRR?)
system that gives you a warm feeling that while contributing to the
general cause, you are building your image.
Actually, it works fine if you only do Git stuff. However, I tried
to pull my Subversion repository using git-svn clone. And this is what
I got:
Can’t locate Error.pm in @INC (@INC contains: /usr/lib/perl5/site_perl/5.8.8 /usr/lib/perl5/5.8.8/i486-linux-thread-multi /usr/lib/perl5/5.8.8 /usr/lib/perl5/site_perl/5.8.8/i486-linux-thread-multi /usr/lib/perl5/site_perl /usr/lib/perl5/vendor_perl/5.8.8/i486-linux-thread-multi /usr/lib/perl5/vendor_perl/5.8.8 /usr/lib/perl5/vendor_perl .) at /usr/lib/perl5/vendor_perl/5.8.8/Git.pm line 93.
BEGIN failed—compilation aborted at /usr/lib/perl5/vendor_perl/5.8.8/Git.pm line 93.
Compilation failed in require at /usr/bin/git-svn line 45.
BEGIN failed—compilation aborted at /usr/bin/git-svn line 45.
Nice. :(
Trying to find Error.pm and install it turned out to be a nightmare -
and I decided to wake up before spending more than 2+ hours trying to
make this work. I’ll just take the current state of SVN repository
and import that into Git as a starting point… losing a year’s
worth of history.
Nevermind, life goes on. I hope Pat will fix
this in next Slackware release.
I’m not using virtualization that much (every once in a while
to test some software on different platforms), but I was a big fan of
VMWare. Although some of it’s components are a PITA to set up on
Linux, it still works much better than QEMU (yes, with all the kernel
drivers and stuff) and it doesn’t require me to recompile my kernel
like Xen.
However, there’s a new kid on the block:
VirtualBox. At first it didn’t promise much, but that was only
until I installed it…
Now, this is what I call USER FRIENDLY application. While
I’m sure VMWare is great on Windows, on Linux its setup simply
sux (in case you wish to only use freeware stuff). To get more to the
point, VMPlayer and server tools are free. So, in order to use it like
that, you can for example use QEMU’s tool to create a blank .vmdk
file and then run VMPlayer to install OS in it. Also, you need to
answer a lot of useless questions during installation, and you
need to extract host-tools (or whatever is the exact name, I forgot)
from the server .iso file. But, that’s not the main problem.
First main problem is creating and editing .vmx file (by reading the
instructions from the Internet?). Second main problem is creating the
shared folders (i.e. a directory shared between guest and host OS).
And the third main problem is switching between real CD/DVD ROM
device and some .iso file (by editing .vmx file? Come
on).
VirtualBox solves all these problems perfectly. Install is dead-simple.
Creating a new image is only a few clicks in GUI (yes,
even I’m a ‘console’ guy, I like slick
GUI that makes stupid things - stupidly easy to do). Adding host
extensions is a single click
in the menu! Adding CD/DVD device or an ISO image is also
dead-simple. And this brings me to shared folders. It is not hard
to add one, but letting the guest OS know about it is not that easy. I had to look into
manual for that one, and guess what: VirtualBox has one of the best application manuals I ever
read. It’s clear, concise and right to the point. It
does not try to teach you how to turn on the computer like most
of the ‘generic’ manuals out there, nor it tells you
what’s on the screen (we’re not blind!). It gives
the information a regular user would need, questions that might
actually get asked.
Now, as I wrote, I’m not a
hard-core VM user, so it might lack some advanced features I
don’t use. But, for a simple “test how my application works on this or that
operating system” type of job, VirtualBox
is perfect. IMHO, it’s the best VM product for the Linux
Desktop.
I’m working on a project that uses wxWidgets as a GUI library. In it, I have a grid (wxGrid class) that has some of the
cells that span multiple columns. Now, it’s very simple to make it
work when you have a regular wxGrid. But,
when you use virtual storage, you need to go through some steps to make
sure multi-column span is done right.
There is no documentation
on how to do this, so I first googled, and failing to find the explanation
like the one I’m about to write now, I experimented. Finally, when
some things just didn’t work right, I had to dig into the wxGrid
code to find out what is the correct way to do it.
If you ever
used virtual grid, you know that you need to have a class that derives
from wxGridTableBase. I have
it, and in my class I override the function GetAttr to get various
effects at runtime (saving both on memory and speed). In this function
you can set the cell attributes (color, font style, etc.) by reading
the info from your own virtual storage (this can be very useful if
you want, say, negative numbers to be red). Anyway, in this class
you use an object of class wxGridCellAttr, set its attributes
and return pointer to it. Make sure you use cellAttriM->IncRef(); before
exiting, since the caller will call DecRef() after using the info to
render the cell on screen.
Now, on to the cells that span
multiple columns or rows. To create a cell like that, you need to
set the attribute for that cell, but also for all cells
it ‘covers’. All this is done via SetSize() function on wxGridCellAttr
object.
Let’s take for example a cell that spans one
column and two rows: a cell at coordinates (3,5). This means that
cell at coordinate (3,6) would be covered by this. So, for the
cell at (3,5) you need to use:
cellAttr->SetSize(2, 1);
and for the cell at (3,6), you need to use:
cellAttr->SetSize(-1, 0);
This -1 and 0 is crucial for selection and cursor movement to work
correctly. If your cell spans even more cells, you need to SetSize for
all of them. For example, if the cell in above example would span 3 rows,
the row at (3,7) would need to use:
cellAttr->SetSize(-2, 0);
Hopefully, something like this will be added to wx manual one day.
Until that happens, read my blog ;)
New version of Slackware, and need to compile Workrave from sources
again (package I made for 12.0 does not work due to a newer Gtk version).
After a lot of experimenting, here are the versions that work
together:
Some time ago I had a lot of problems viewing some H.264 or x264 files.
Apparently, my favorite video player, mplayer does not support the complete
H264 specification, so it has problems with some of the files out there
(reads in the length wrong so you cannot move to, say, middle of the file;
audio and video goes out of sync, etc.)
So I turned to other
solutions. Xine fall flat on face as well, and although ffmpeg plays
it fine it doesn’t have fast forward/rewind and fullscreen option
that is actually usable.
The thing that worked out is VLC,
which I first had to confirm on Windows, since it was much easier to
set it up there. Making it work properly on Slackware was not easy.
After having problems with prebuilt packages, I decided to roll my
own.
I do a lot of wxWidgets development myself, so I used
an already built wx version 2.8.7. VLC compiled, but crashed at
startup (I got segmentation fault with vlc, wxvlc or svlc). I
looked at the website, and it says wx 2.6.3. That one is buggy
unless you patch it (patch is at wx website), so I first tried
with ‘safe’ 2.6.2 which has proven to be rock solid
in the past. However, 2.6.2 doesn’t compile with Slack
12.1’s default GCC 4.2.3, so I went for wx 2.6.4, which
turned out to be a right choice. Just make sure you build wx
in release (not debug) mode, as there are some problems with
wxLog functions and VLC.
Here are the relevant versions
that are compatible:
Slackware 12.1 (with various media codec for 11.0 and 12.0 installed from linuxpackages.net)
Making Audacity work on Slackware 12.0 is an adventure. I’m
using wxWidgets for some development myself, so building Audacity from
sources shouldn’t be a problem. I used Audacity 1.3.4. Now, onto
the issues:
Audacity 1.3.4 has a known bug that makes it’s
compiling fail. If you see this:
> import/ImportMP3.cpp:
In function ‘void > GetMP3ImportPlugin(ImportPluginList*, >
UnusableImportPluginList*)’: > import/ImportMP3.cpp:52: error:
‘DESC’ was not > declared in this scope >
import/ImportMP3.cpp:52: error: ‘wxSIZEOF’ was
not > declared in this scope > make[1]: *** [import/ImportMP3.o]
Error 1 > make[1]: Leaving directory >
`/home/milanb/install/audacity-src-1.3.4-beta/src’ >
make: *** [audacity] Error 2
Now, after I built everything, I started it only to realize that is has no MP3 support. It turns out MAD library is to be used for this, but although I have it installed the configure script doesn’t detect it. It looks for libmad using pkg-config, but the vanilla libmad doesn’t register itself with pkg-config. Cool, eh?
Apparently, Debian package for libmad adds this entry, but the patch hasn’t made it into upstream (yet?). In the end, I blame Audacity developers for not using some other way to check for libmad - at least they should until pkg-config stuff is part of the official libmad release. But, maybe it’s simply because they are using Ubuntu or Debian and they are completely unaware of the issue.
But, lets just get this working on the Slackware. Here’s a nice patch for libmad 0.15.1 (currently the latest release) that adds the pkg-config stuff to libmad:
So, just download the libmad source, patch it, build and install (before building I ran autoconf and automake, just in case) and Audacity’s configure script will pick it up.
I had a problems with ReiserFS losing data when power failure occurs.
Finally, I got to learn the details why it might happen:
XFS only does metadata
only journalling. ext3, ext4, and reiser3 can do full data journaling.
They will also do metadata journaling with ordered writes, and, of course,
just plain metadata journaling.
metadata only: If you lose power,
the filesystem structure is guaranteed to be valid and does not require an
fsck. Actual data blocks may contain garbage.
Metadata with ordered
writes: If you lose power, the filesystem structure is guaranteed to be
valid and does not require an fsck. The data blocks may or may not contain
the very *latest* data. They But they will not be garbage.
Ext3
defaults to ordered. Not sure about reiser3.
So XFS (and JFS) can
leave garbage in the datablocks after an upplanned shutdown. But it gets
worse. Due to a design decision, on remount, XFS actually nulls out any
blocks that were supposed to be written that didn’t actually get
written. i.e. if you pull the plug during a write, you are pretty much
guaranteed to suffer data loss. If random chance does not leave garbage
in a block, the filesystem will thoughtfully zap your data intentionally.
This is done for security reasons.
Obviously, ReiserFS 3 does not default to ordered writes, and
that’s why I got garbage (parts of different files mixed up). JFS
and XFS seem even more dangerous, so I guess I’ll stick with Ext3
from now on.
I wrote about GCC C++ compiler (g++) before and was really unhappy
how slow it is compared to commercial compilers (MS Visual C++ and
Borland’s C++).
Today I tried building FlameRobin with
MSVC Express. It works really nice and it builds FR from scratch in
about 2.5 minutes on this machine where I tried it (Intel Celeron M
1.4GHz with 256MB RAM). This in on Windows XP Pro with all anti-virus
and similar software turned off.
Then I tried on Linux (it’s
a dual boot machine) and GCC took 272 seconds, i.e. 4.5 minutes. Both
compilers are using PCH. I got really frustrated about this in the past,
so much that I considered to install Windows on my machine and do FR
development there.
But, I suddenly got the idea that GCC might
be losing too much time optimizing. So, I tried to lover the optimization
from level 2 to level 1. I got slight improvement: 225 seconds. Still too
slow. Then I turned it off, and I got the amazing 130 seconds, i.e. 2:10.
This is quite acceptable to development and I guess I’ll only use -O2
when we build the release versions from now on.
The option can
be changed by setting CXXFLAGS environment variable before you
run ‘configure’ script. Something like this (if your shell
is bash):
$ export CXXFLAGS=
$ ../configure …
$ make
It looks like GCC C++ compiler isn’t that bad after all.
I won’t be switching to Windows any time soon.
While working in FlameRobin I often run into DnD bug that locks up the
screen completely. Something takes over the mouse input (it’s called
grab) and the only way is to kill FR. It happen often when DnD is enabled,
but also sometimes when it is not.
Looks like we aren’t the
only ones affected by it. Here are some examples of Evolution team, having
the same problem:
gtkhtml.c:
static gint
idle_handler (gpointer data)
{
GtkHTML *html;
HTMLEngine *engine;
+ GDK_THREADS_ENTER ();
...
+ GDK_THREADS_LEAVE ();
return FALSE;
}
idle_handler() was missing surrounding GDK_THREADS_ENTER / _LEAVE calls. Due to
this, idle_handler returned and left the global mutex locked, however it should
have been unlocked because idle_handler was called from the idle loop. As the
>mutex was locked, when GTK+ tried to acquire the lock again the thread got
locked (as seen on the previous stack trace).
I just have no idea, where in wxWidgets source do we need to insert
those guards. Also, here’s another report:
I think Gavin has right. Based on the documentation for signals "drag-drop" and
"drag-data-received", gtk_drag_finish is supposed to be called in one of this
signal handlers to let the source know that the drop is done. Evolution do this
too late, from my point of view, so it breaks this rule and when dragging next
message the call for gtk_drag_finish breaks UI.
It seems vanilla Evolution has fixed it now, although some distro-patched
versions still exhibit the problem.
Looking for some cool domain to register, I tried misterx.com and got this:
Registrant:
Mister X
1201 Edgewood St.
Johnson City, Tennessee 37604
United States
Registered through: GoDaddy.com, Inc. (http://www.godaddy.com)
Domain Name: MISTERX.COM
Created on: 03-Dec-98
Expires on: 02-Dec-12
Last Updated on: 27-Nov-07
Administrative Contact:
X, Mister vaughnt@iplenus.com
1201 Edgewood St.
Johnson City, Tennessee 37604
United States
423-232-0178 Fax — 276-475-3811
This can be
nice for some tools whose returned value you are not interested. For
example, I use make to automate some of my work, and I use this to print
diff of two files, who are expected to differ.
Prepend
‘@’ to prevent printing the command
Mostly used
with ‘echo’, so that the same thing isn’t printed
twice.
To re-run configure (I use this for FlameRobin) with
same options:
alias regen=’`head config.log | grep opt | sed “s1.*.1..1”`’
Please note the grep opt part.
It needs some text from original configure line. I use opt, since wxWidgets
is installed under /opt for me.
If you are involved in software developement and you don’t know who Joel Spolsky is, you’re missing a lot. Here’s another great article of his. This section is a thing one needs to remember:
Software development takes immense intellectual effort. Even the best programmers can rarely sustain that level of effort for more than a few hours a day. Beyond that, they need to rest their brains a bit, which is why they always seem to be surfing the Internet or playing games when you barge in on them.
Today I begin my trip into Slackware 12.0 on my workstation.
It’s an older machine:
Pentium III 550MHz ATI
RADEON GPU 265MB RAM 40GB HDD
In short: Slackware
12.0 with KDE 3.5.7 runs quite smooth on this machine - having 256MB of
RAM is crucial.
Installation went fine, without any hickups. I
choose full install and it took about 3.7GB of the disk drive. The first
problem was after reboot. I choose to start gpm at boot time, and it was
messing up the terminal, so ncurses applications would malfuncion. The
main problem is that all Slackware setup tools are ncurses based, and
also is the Midnight Commander. Since I have a brand new monitor
(22” Benq with 1680x1050 resolution), setting up the X server
was a problem (if you don’t know, the great xorgsetup wizard
uses ncurses too). Of course, I didn’t know it was gpm that caused
the trouble, so I tried all other stuff before figuring that out. Perhaps
the main problem is that I have a serial mouse plugged into COM1.
After
killing the gpm and restarting, I was able to run xorgsetup and…
it detected everything out-of-the-box! Excellent! The only thing I had
to change is to set mouse device to /dev/ttyS0 and run startx once more.
My Radeon was detected automatically and resolution set to 1680x1050 at
60Hz. Perfect! It even let me specify different keyboard layouts, so I can
use them outside of KDE.
Now, onto the software. KDE runs fine,
and new Fluxbox is also nice. GQView is included. Yeah!
First
thing needed - Workrave. Now, here starts the show. There is no
.tgz package, so I decided to build from the source. Workrave needs
libsigc++ and glibmm. There is libsigc++ package on linuxpackages.net,
but only for libsigc++ 2.0 (unfortunately I learned that after installing),
so I downloaded the source from Gnome FTP and compiled. All fine. Then I
took glibmm, downloaded the latest version (2.14.0). I ran configure
—prefix=/usr and then ‘make’. One would expect that
Gnome guys are up to it, but it looks like both Linus and Patrick are
right regarding their Gnome vs KDE opinion. Anyway, here’s what I
got:
In file included from regex.cc:4: ../../glib/glibmm/regex.h:29:25: error: glib/gregex.h:
No such file or directory ../../glib/glibmm/regex.h:594: error: ‘GRegexEvalCallback’ has
not been declared …and
few more pages of errors
It looks like the package isn’t able to find its own files. Don’t they the
test thing at least once before releasing?
…this just popped out of my fortunes and I like it so much,
I have to show it here:
An architect’s first work is apt to be spare and clean.
He knows he doesn’t know what he’s doing, so he does it carefully and
with great restraint.
As he designs the first work, frill after frill and embellishment after
embellishment occur to him. These get stored away to be used “next time”.
Sooner or later the first system is finished, and the architect, with firm
confidence and a demonstrated mastery of that class of systems, is ready to
build a second system.
This second is the most dangerous system a man ever designs. When he does
his third and later ones, his prior experiences will confirm each other as
to the general characteristics of such systems, and their differences will
identify those parts of his experience that are particular and not
generalizable.
The general tendency is to over-design the second system, using
all the ideas and frills that were cautiously sidetracked on the first one.
The result, as Ovid says, is a “big pile”.
and it really fulfills the promises. It’s just great, at least, what I discovered so far.
The main reason for me to try it out was simulatneous SATA and SMP support. It’s worked out-of-the box, I just had to pick a right kernel. Seeing the four penguin images coupled with fast-boot time is really delightful.
But, that’s not all. The other usual stuff seems to work ok, and new KDE seems a little bit faster (not! because of 4-core CPU - I also installed it on my old Pentium 3 laptop with 128MB RAM). Other things to enjoy in is easy mounting of removable drives - no more dmesg+mount messing. Although, I somehow managed to get that working properly on 10.2 with 2.6.13 kernel by manually configuring the udev rules - but don’t ask me to repeat it on another machine :)
I still have to try new GCC. That would remove all the problems I had with having GCC 3.3.6 and G++ 3.4.4 installed at the same time, and it also removes the bug with precomplied headers when using wxWidgets i Unicode mode. Well, I did use GCC 4.x before but compiling it myself from sources and running in sandbox environment, but that’s just not it.
I’m currently messing up with Bluetooth dongle. Bluetooth support comes with Slackware 12.0, but tools are…. well, there are no GUI tools, you have to go to the command line. I just learned about l2ping, hcitool, rfcomm, etc. and it looks like some things are going to be tricky to do as a regular user as some /dev entries get root:root owner and 660 permissions… But, more on that later after I get it to work. Actually, it does work (ping, querying services, etc.) but I want to make a dial-up connection using KPPP. I’m almost there (modem interface responds, and seems to dial, but pppd dies), so I’ll probably write more when I finish it.
I expected much more instability given the fact that so many things are new and untested, so I was considering to wait for 12.1 or 12.2 before installing it as my main system, but now I’m having second thoughts about that. As I’m changing my main work machine and installing something from scratch on it, it will most probably be Slackware 12.0.
The
Open Virtual Machine Tools (open-vm-tools) are the open source implementation of
VMware Tools. They are a set of guest operating system virtualization
components that enhance performance and user experience of virtual
machines. As virtualization technology rapidly becomes mainstream, each
virtualization solution provider implements their own set of tools and
utilities to supplement the guest virtual machine. However, most of the
implementations are proprietary and are tied to a specific virtualization
platform.
With the source code readily available, users of VMware
products today (and other virtualization platforms too, in the future)
will get these tools bundled and delivered through their distribution
specific package manager. This should provide a seamless installation/upgrade
experience and ease the burden on sysadmins. In fact, if you are looking
to package the source for your favorite Linux distribution, we have
included some helpful documentation.
and it just flies. The great thing is that technically superior
VMWare technology goes open source and all those threats from Microsoft or
Xen about putting them out of business soon became completely void now.
Some time ago I did a benchmark comparison of VMWare and QEmu (using
kqemu acceleration). I get asked about it so often, that I decided to post
it on the blog. My tests involve memory and CPU intensive operations like
compiling, so it might not be what you’re using your virtual machine
for, but I only use VMs to test my applications on various platforms. Host System: Slackware 10.2, vanilla 2.6.13 kernel
that comes with it RAM: 512MB CPU: AMD Turion64 MT30 It
is a 64bit CPU, but I only run 32bit OS.
Software: QEmu 0.8.2 - using slack10.2 package from linuxpackages.net:
qemu-0.8.2-i486-1gds.tgz KQEmu 1.3.0 pre9 - compiled from
source from kqemu-1.3.0pre9.tar.gz VMWare Player 1.0.3 build-34682 -
installed from VMWare-player-1.0.3-34682.tar.gz
Since Slackware
doesn’t have SysVinit, before installing vmplayer I created
directory /opt/vmware
and
subdirectories rc0.d, rc1.d, rc2.d,
rc3.d, rc4.d, rc5.d, rc6.d.
When wmplayer installer
asked, I gave it /opt/vmware directory.
I aslo installed
vmware-tools. I extracted the .iso file from vmware-server
package, and installed it inside guest system.
On
each test I freshly unpacked the archive and ran:
$ time -p ./configure
I also rebooted the machine to make sure VMWare and QEmu don’t interfere with each other.
Host system: 51.44
QEmu (kqemu module loaded): 1962.29
QEmu with -kernel-kqemu: 1471.51
VMPlayer: 587.20
As you can see, GCC in virtual machine performs 10x slower than on real computer. I really like VM technology and it has good uses for testing and QA, but I really don’t understand people using it in production. Hardware is cheaper than ever and with VM you also have a single point of failure - if some hardware component fails, instead of losing one server, you lose all of them.
Yesterday I had to install Linux on a Intel Core 2 Duo machine with
SATA disks. So, I figured I need both SMP and SATA support. My
trustworthy Slackware 10.2 seemed out of the question, or shall I
rather say: out of date. So I went for 11.0 as I didn’t have
12.0 DVD at hand and this was supposed to be a quick installation.
Well, it turned into a 9-hour marathon, ending in me giving up on SMP
at the end (until I try with Slackware 12.0).
Slackware 11.0
comes with 15 or so kernels. All but two of those are 2.4 kernels. Non
of those 2.4 kernels supports the SATA controller in that machine. So,
I had huge26 and test26 to test. The huge one should work on any machine?
Couldn’t boot this one (Asus/Intel965, JMicron SATA controller).
Pluging SATA disk into Intel ICH8 rather than JMicron fixed that and I
was able to boot with test26.s. Unfortunately, after booting, there was no
way for it to see the DVD ROM that was connected to PATA IDE. Going back
to Bios and trying both compatibility and enhanced modes didn’t help
at all - most of experiments with BIOS settings ended up in not being able
to boot with any kernel. BTW, each time we changed a single setting in BIOS
we rebooted and tried all of: sata.i, bare.i, test26.s, huge26.s and the
only one that would sometimes work in test26.s. I’m inclined to say
that sata.i kernel in Slackware 11.0 is next to useless.
In
the end, we managed to find an USB DVD reader and decided to copy the DVD
image to hard disk (as we had to return the USB DVD reader, we couldn’t
affort to play and try to install from it). Now, we learned some more
interesting things. For example, I ran fdisk and created 3 partitions.
Formatted one of them as xfs (default option in Slack11) and ran:
dd if=/dev/sdb of=slack11dvd.iso
All was going nice until slack11dvd.iso reached 2GB file size. Now, it
was my first time using XFS and even though I know I read people having
huge files on it, I just figured that something might be wrong and
reformatted the partition to ext3 and start over. No luck, at 2GB mark we
got the same error. Ok, at this point I concluded that dd on Slackware
11.0 installation disk does not support files larger than 2GB. So I
mounted the DVD and used ‘cp -a’ to copy it over.
Next,
I started ‘setup’ and go to the point to select media. Tried
with ‘directory on local disk’ option (can’t recall the
exact wording) and it gave me various errors before I gave up on it and
selected the ‘pre-mounted CD or DVD’ or whatever it is called
exactly. In the end I had just deleted the /var/log/mount (or something
like that) directory where the installer expected to find the directory
structure and symlinked that to that DVD copy I made with ‘cp -a’
earlier. It’s so cool that Slackware’s installer is a shell
script and you can use ‘vi’ to peek inside and find
easy ways to trick it into doing what you want it to do. Another cool
thing is that Slackware gives you usable consoles while installing (available
via alt+Fn combinations). Finally the Slackware installed.
Rebooting
is a whole new story. As I was scared to choose kernel from CD during
install (didn’t know if it was going to try searching the CD device again),
I told it to just go with vmlinuz. It couldn’t boot, so I booted from
DVD, went in, replaced default kernel with test26.s, run lilo and rebooted
again. Now we now had a running Slackware 11.0 with SATA support. Great? Not
yet.
Of course, test26.s kernel doesn’t have SMP support
some one of our CPUs was simply just lying there dead doing nothing at all.
Looking at various precompiled kernel options, I found 2.6.17.13-smp. Tried
it - of course - no SATA support. At this point, some 4 hours have already
passed, and I was looking at a choice: add SATA support to SMP kernel, or
add SMP support to SATA kernel. The former seamed feasible, the latter
impossible. Ok, I just figured that I need to add some modules for SATA
stuff into kernel core and be done with it. But that would require to
compile the entire kernel and I wasn’t really in a mood for that.
Then I figured that we have to use initrd anyway, so why not just load sata
drivers in it. Seemed like a best idea of the day. BTW, by now I learned
the mkinitrd line by heart:
This is the default line. To add more modules, simply add their names
(filenames of .ko files) to the list in -m option. So I added sata_mv as I
mistakenly thought that SATA controller was involved.
Ran mkinitrd,
lilo, rebooted… kernel panic.
Booted from DVD
again…this time reading all the output of boot process (and later
analyzing dmesg). It’s nice that test26.s successfully loads almost
all SATA stuff (not modules - it’s built in) without errors - so
it’s really hard to determine which of those is really used. lsmod
cannot help at this time. If you knows how to get ‘lsmod’
for stuff that is compiled into the kernel PLEASE LET ME KNOW.
So,
I started adding stuff to the -m line of mkinitrd. Some of the modules
I recognized instantly, for others I used ‘grep’ in
/lib/modules to find out. I the end I had about 12 modules, output of
loading process was quite similar to the one of test26.s but still it
wasn’t able to see the SATA disk, and still wasn’t able to
boot. The only module making problems was ipr (some IBM’s SATA
controller I believe), but I wasn’t able to determine why it
cannot load. Looking at modules.dep it didn’t seem that it has
some dependent modules that I need to preload before it.
I
also had problem with my network card not being supported by test26.s,
which is (if someone wonders) kernel 2.6.18. But that’s a minor
issue as the card is supported in 2.6.20, and one RTL8139 is doing the
job in the meantime.
The current state is that we’re
running with SATA disk and one CPU and PCI Ethernet card. I’m
looking forward to Slackware 12.0 and 2.6.21 kernel which should solve
this.
One of the things I hate recently is flash banners on websites. Sometimes I see something useful and want to visit the link. But, right-click doesn’t open the browser’s (Firefox/Mozilla) context menu but rather Flash context menu. As if I even wanted to rewind a flash movie (most of them have playback control of their own anyway) or change quality or whatever.
I just want to open the darn link in a new tab. If anyone knows how to disable flash menu and have my Firefox menu back, please let me know.
Today I got completely frustrated with GCC. I was doing some coding
on FlameRobin, changing just a single file. Save, run make - it takes
1.5 minutes or something for thing to get compiled and linked so I can test
it. I have a 1.6GHz CPU with 512 MB of RAM. Now, how could it be that
slow. But, one thing caught my eye: while linking the hard disk would work
like crazy. I looked and there was no swap usage, but RAM was used 99%. No
swapping, but obviously it had to release stuff from the cache and load it
back in.
Time for testing
I deleted the
executable and ran ‘make’ again. It took 55 seconds.
Too much. Ok, I closed down the browser, music player, even text editor.
New run: 43 seconds. Not good enough.
At this point I decided
to kill the beast. I shut down KDE, went back to console and
installed IceWM. Got back to X, installed SciTE to use it instead of
Kate (perhaps I should learn Emacs one of these days). Launched
Mozilla to blog about this and xmms instead of JuK. Run the experiment
again:
milanb@asus:~/devel/svn/flamerobin/rel-gtk2-wx280$ time -p make
g++ -o flamerobin flamerobin_addconstrainthandler.o flamerobin_Config.o
…etc.
real 10.90
user 8.45
sys 2.07
ahahaahhaaaa.
Well, quite enough reason for me to go
back to IceWM, at least while developing in C++. Ok, now the real problem
is Workrave which (from reasons yet unknown) loads kdeinit and two more KDEdeamons with it.
Perhaps I should just get 2GB of RAM and forget about the whole problem? Only thing bothering me is that this machine is a notebook, so it isn’t so easy to upgrade.
One thing really starts to go on my nerves. All the e-banking applications used for companies (personal e-banking is OK) seem to require that you run them under Windows. It amazes me how you should run your most sensitive stuff on most insecure possible system. Even if we handle the e-banking application issue (some of those are web apps., so you only need a browser), we still have a hardware issue as most of the smart-card readers used for authentication, only have drivers for Windows.
I don’t know if IT people who make applications have any valid excuse. Their arguments range from everybody else does it to most of our users require Windows version. Or perhaps there just aren’t enough skilled programmers in the industry who are able to create Linux or Mac versions? Now, what’s the whole problem? Well, in order to get the financial data, you need to access Internet from such machine. In turn, that means you’re vulnerable to any new exploit - which are abundant to say the least. In order to transfer the data to the rest of the network, to people that need it, you connect such machine, and potentially expose the entire network to problems. Looks like that Windows machine doing e-banking needs DMZ configuration of it’s own.
Just another example of follow the crowd syndrome having bad effects.
I needed to create some sprite
animations, so I decided to use something existing instead of
writing my own. Good animator isn’t only able to animate
pictures, but should also have image editing abilty, so that you
can change and test in most productive way. I found that Gimp has
such plugin, so I decided to give it a try. It does work, but I ran
into several problems:
1. Image size. When set to animate,
the Videoframe Playback window only allows images to be bigger
than 64x64 pixels. Why is this limitation escapes me. My sprites
are 25x25 and look very ugly especially since enlargement to 64x64
blurs the pixels.
2. Nagging audio dialog. Yes, every time
I run the animation I get the stupid:
No audiosupport
available the audioserver executable
file ‘wavplay’ was not found. If you have
installed ‘wavplay 1.4’ you should add the
installation dir to your PATH or set environment variable
WAVPLAYPATH to the name of the executable before you start
GIMP
…message, and have to click OK. No I
don’t have it installed, I don’t want to install it
and I don’t need audio. I just want to animate a bunch of
25x25 sprites for my game. Even better, the Enable checkbox
on audio tab isn’t checked. Looks like the authors want us to
use the cool audio feature so much, that they made the whole animation
thing quite annoying if you decided that you don’t need
it.
3. Gimp has some cool animation stuff
in Script-fu -> Animators. The only problem is that
it creates the animation frames as image layers. Apparently, the only
way to make animation from it is to manually copy/paste each of those
layers to animation. Not much fun when it has 20+
frames.
Anyway, I’m looking for a replacement,
if you know any, please let me know.
I
decided to try to go into shareware business on Linux. Many people
are complaining that Linux is hostile ground for shareware authors
and it is possible so. I guess that Linux users are used to have
things for free, well at least I have. But it also gets us to the
point where some kind of “boring” software isn’t
available on Linux. By “boring” I mean in the sense that
such software is “boring” for developers to make, and
they would probably never do it for fun, but rather expecting some
money in return.
There were times when only a few companies were
making laptop computers. They gave much thought to it and gained big
experience. You can still see some of those old rusty machines running.
Today, there are many manufacturers, but they have a long way to go and
some basic things to learn.
Take this photo for example.
It’s my 5-year old Compaq Evo N160, and that’s why the
arrows on arrow keys are not there anymore. It was my first
notebook so, coming from a regular PC, I was a little nervous about small
keyboard, lack of numeric keys, etc. I thought to myself: look, they
even wasted two free places above the cursor keys (left and right
one). It wasn’t until recently that I realized how genius this
design is: I bought a new Asus A6000 series laptop. Very cool machine,
and those two spots were used to Fn and Windows menu keys.
First time I wanted to work at night - the problem has shown up:
It’s darn hard to find cursor keys in the dark.
Being a
programmer myself, cursor keys are probably the most important ones,
as you move around in source code all the time. Having to look where
they are is a real pain. With old Compaq, my right hand would just go
down until it finds those two empty spots. Working without it is
a real pain. So, finally, few months later I couldn’t bare it
anymore and I decided to yank out the Fn key - I have another one
in the bottom-left corner of the keyboard anyway. Anyway, this example
shows experience in some field is also important in hardware industry.
Today I decided to play with udev and make sure that my multi-card
reader automatically detects the device and make it available under
/dev/memory_stick. Knowing a little about it, I decided to RTFM. So,
I typed “man udev” and it goes:
“udev expects its main configuration file at /etc/udev/udev.conf.
The following variables can be overridden in this file:
…
udev_log
The logging priority which can be set to err, info or the corresponding
numerical syslog(3) value. The default value is err.”
Ok, cool, so I went to /etc/udev, opened the udev.conf file, and it says:
# udev_log - set to “yes” if you want logging, else “no”
udev_log=”no”
Lately I seen reports about various distributed version control. Although it seemed useful (you can work on train argument), I didn’t see any real benefit or reason to use it myself. Until today.
On my laptop I have multiple operating systems installed as virtual machines. I do the developement on main (host) system, and then try to deploy on various guest systems to see how stuff works. And sometimes something just doesn’t work. So I have to change it in host system, copy to guest, recompile and try it. When you have to develop large piece of software for multiple platoform this becomes tiresome.
And then I figured it out. I setup the guest system to fetch code directly from main repository, did the changes on guest system, and when it worked fine I commited changes to main repository. There are two problems with this:
a) you must commit while working, i.e. you commit unstable code. This basically means you need to branch for each small feature you’re working on - which sucks.
b) if the repository is unreachable (i.e. you DO work on train, or don’t have Internet access for some other reason) you cannot basically do it, so you have dicrepancy between version in guest and host system.
So, I set up the local Subversion repository and worked there, which turn out to be great. However, the problem is migrating those changes to main repository when done. This is exactly the problem that distributed version control systems solve.
Now, I have to decide which one to use. If you can recommend some good, reliable, distributed version control system, please leave the comment and pros are cons of using it.
Kompare is a
very useful piece of software and I could hardly live without it. It
really good when you need to visually compare two source trees or
simply two files. You can also use it to apply differences to one of
the files. There are three things that I don’t like about it:
It only allows to apply changes in one direction. The excuse might
be that it makes sure you don’t change the file you don’t
want. Other tools I’ve seen (WinMerge) simply have a checkbox
saying “read-only” on both sides, so you can easily
decide which one of “source” and which
is “destination”
The other thing is that many times I have changes in both files
at same places. Kompare selects a large chunk of code as a single
section. What I’d like is to be able to select some lines from
that chunk and only add those to the destination.
As I wrote, I make changes to both files at same place. Sometimes
I just need to add a line from “source” without
overwriting the “destination” file. However, that
doesn’t seem to be possible with Kompare.
There are great development
tools on Linux, but they really need some polish to be excellent tools.
Sun open sourced Java recently. At first I didn’t really care much about it, but now I started thinking. From what I know, few years ago, Microsoft lost a law suit regarding Java technology and they removed it from their operating system. This meant that you didn’t get Java with Windows default installation. I also believe that it’s one of the reasons Microsoft created .Net stuff.
It would be interesting to see Microsoft’s reaction to this. Will new versions of Windows include Java by default. Too bad that Vista is already out and who knows when we’ll have a new version of operating system from Microsoft. Maybe in another five years. It makes me wonder did Sun really have bad timing with this or they did it on purpose? Who knows, maybe Microsoft don’t care much about Java anymore. I see them pushing .Net really strong.
Workrave is one piece of software I use all the time. It’s a
program that assists in the recovery and prevention of Repetitive Strain
Injury (RSI). The program frequently alerts you to take micro-pauses,
rest breaks and restricts you to your daily limit. Great stuff and it
saves my eyesight from getting any worse (beside other things).
The
only problem is the one I have with Linux version. When it pops up
micro-break, I can click the rest break button. However, at my
job, I allowed rest break to be cut off, as I could have a client on the
phone, and it’s not a good idea to keep them waiting. So, basically
I can kill off the micro break, which is bad. I’d like program to
force me to have that microbreak. So, it’s O.K. for micro break to
have a rest break button, when when I enter rest break from there I
should only be able to go back to micro break, and in no condition be
able to break from it completely.
After few months of hard work, my latest project is finally
done. It’s a space
shooter game, but has some strategic elements that make it
unique. Gameplay consists of general story and trading system like the
famous Elite, however, in-space part is not Elite’s dogfight but
rather an arcade shoot’em-up like Space Invaders or Galaga. Check
it out at
My apologies to everyone who posted comments, and to all of you who were awaiting new stuff on the Blog. Reason for the first thing is that I didn’t migrate blog to new Google blogger and I didn’t get any notifications about comments you made on the website. I’m sorry about that, although it is not my fault.
I migrated to new blogger now, so hopefully everything will be ok.
As for the new stuff, I was way to busy in past two months, and slow blogger interface also put me off a lot. I’ll soon post some new articles and hopefully new blogger works faster.
From what I read, MS and Novell plan to develop their own additions to OpenOffice, Samba and Mono. OO and Mono are LGPL, so MS and Novell can safely build their own proprietary technology and dynamically link with OO and Mono source code given by the community. I guess they can easily put the entire OO into a bunch of .so files and load them dynamically from their own office suite. They can also integrate those with their own proprietary format in new versions of MS Office. That way MS Office and their Linux version of office suite would be 100% compatible. However, if some non-SuSE distribution would want to use such office suite they would have to pay royalties.
As you can see, MS idea is not to kill Linux, as they have obviously seen it is impossible. So, they decided to integrate those few important software that are main revenue source for MS, and make Linux users pay one way or another.
Soon, MS won’t be telling: don’t use Linux. They embrace Linux users, as it means more money for their office suite - which is the main source of revenue (unlike cheap OS).
As for Samba, which is GPL, MS could easily change the protocol in it’s Windows systems (perhaps it is already done in Vista???) and patent the new protocol, effectivelly pushing Samba team out. Then, they’ll provide their own version of Samba, possibly writing it from scratch (as MS has a lot of programmers, it isn’t a problem) which would use their proprietary and patented protocol. Once again, Linux users would have 100% compatibility, but at a price.
I find k3b to be the best CD/DVD burning software I’ve ever
seen (both on Linux and Windows). It is nice, slick, fast, stable and
works just as it should. There is only one minor glitch bothering me.
The darn 100% marker in bottom-left corner of file browser. It sits there
and always covers one of the files or directories. Many times I need to
select that file or enter that directory. You can’t remove it by
clicking or anyhow.
I just finished reading the last, 6th book of Frank Herbert’s
Dune series. Excellent stuff, they say Frank Herbert is to Sci-Fi what is
Tolkien for Fantasy. Anyway, during the course of reading the books, I
complied a list
of memorable quotes (warning: design of that page might make your eyes
hurt). They are not grouped, but rather in the same order they appear in
the books (with little shuffle to put similar things together).
After
playing the Dune game and watching the Dune movie, reading the Dune
books concludes it. BTW, while reading I listened to Iron Maiden music. It
goes together very good (if you like heavy-metal, of course).
The more I learn about AJAX (I’ll soon have
it fully implemented in some of my applications) the more I develop a
view of it. AJAX looks to me as interactive web service. A web service
to which you can send the request and it provides. But it doesn’t
require reloading of web page. Powerful indeed.
Looks
like I’m not the only one thinking that way. I just found a very
interesting website:
In the past few years, the only computer game genre I still play occasionally are the turn-based strategies. One of my favorites is The Battle of Wesnoth, which is now at version 1.1.8. It is open source game and has made of lot of progress. Graphics are much better now than before and it is really well polished. I highly recommend it to anyone who like turn-based strategies.
I just finished the main Heir to the Throne campaign. Here’s my recall list before the final battle (level 1 units excluded):
3 x Paladin 2 x Mage of Light 1 x Elvish Champion 1 x Elvish Avenger 1 x Elvish Ranger 1 x Elvish Shyde 1 x Dwarvish Lord 1 x Dwarvish Dragonguard 1 x Dwarvish Thunderguard 1 x Merman Warrior
Well, make sure you try it if you haven’t already. Be prepared to neglect your family, or even worse: play together with them (as allies or foes).
Nope, this isn’t going to be one of those flamebaits trying to convice you which one is better.
Each night I turn my DVD recorder off using its remote control (I use it to switch channels instead of TV’s one). I usually do it in the dark, and I usually open the disc tray first before cursing the fact that the power off button is on the other side. Other from what? Well, from TV’s remote which I used just a few seconds before - to turn TV off.
There’s obviously no standard between makers of TV sets and DVD recorders, but this thing often reminds me of a similar issue in software: the button placing in KDE and Gnome. For those of you how don’t know, KDE and Gnome have different standards on button placing in dialogs. Beside other minor things, OK and Cancel buttons are at opposite places. Of course, both camps are right, and there is no standard here, just what you might get used to.
Many people get annoyed by Gnome’s positioning because it is different from MS Windows. I’m not one of those people, but I do get annoyed when two applications I’m using simultaneously have different setting.
It all goes down to underlying toolkits: Qt and Gtk. Now, in my not so humble opinion, instead of trying to duplicate each Gtk app in KDE, and each Qt app in Gnome (often in much worse quality) developers should play smarter and get apps to adapt to the environment. It would be cool if Gtk and Qt could simply ask the window manager: “what is thy button placing preference?”. If it doesn’t respond (i.e. doesn’t have it), it would use the default placing used so far. Otherwise, the appopriate placing would be used and if I’m using KDE, then Gtk apps. wouldn’t stick out. Conversely, if I’m using Gnome, Qt apps would blend in.
I understand that this might not be easy. There is a whole new interface to implement, and some apps. might need to standardize their dialogs first (which makes all this a good idea after all)
Q: What’s the worst thing that
could happen to you on Linux? A: I don’t know, but not having
any more disk space on root partition is disasterous.
It
happened to me once again. This time, it looks like I only lost my
/etc/hosts file. I was just about to edit it, and tried first with vi.
First I mistyped the filename:
milanb@asus:~/devel/svn/ibpp-current$ su
root@asus:/home/milanb/devel/svn/ibpp-current# vi /etc/host
blkwrite failed
Still, not thinking about this strange error message, I tried again:
root@asus:/home/milanb/devel/svn/ibpp-current# vi /etc/hosts
skipping 1 old session file
blkopen’s read failed
Ok, I tought to myself, something’s the matter with vi. Lets use
the second option, mcedit (part of Midnight Commander). What a horrible
mistake that was:
root@asus:/etc# mcedit hosts
It opened the file properly. I made the changes and pressed F2 to save.
It reported some error that it cannot save it. Ok, nevermind, I exited
the editor and to my big surprise: file is truncated!
Aaaargh. Now I have to try to remember what was there (I don’t
backup each and every file on each and every machine I have).
P.S.
The screenshot: before posting to blogger I usually write the text in
editor, especially when system seems unstable (I was still unaware that
the root partition is full). KWrite was nice to let me know what is
happening. I guess sometimes I’m too lazy to think, and the good
thing is that there are programs like KWrite that think for us :)
I use Firefox as my main web browser, and when it comes to download, I use it’s own download manager. I’m aware that there are a lot of download-manager extensions available, but I hate to have to go through the process of evaluating each one. I did try a few, but they were no good, so I gave up. Besides, one has to keep track of those extensions when installing new versions or switching computers. (If you’re going to recommend me some, please keep in mind that I use Linux/KDE).
As for the integrated Firefox download manager, I only require one thing: ability to resume downloads when server terminates the connection, or my Internet connection gets broken, and after restarting the computer.
Other things are ok, I don’t feel the need for multithreaded (a.k.a. accelerated) download. And that bug with simultaneous downloads (see screenshot above) can be misleading many times, so you’re never sure until you open the Downloads window.
Do we really need to have our cell phones
turned into computers?
Not so long ago, cell phones were are
regular “utility” devices. Just like TV, radio, refrigerator
or microwave owen. You plug it in, and it works. There are few options
that you can understand without even reading the manual. Everything
works as expected. Not only that, it is robust, and rarely malfunctions -
when it does, you probably need to buy the new one, as old one is…..
well, too old.
Back in those days, you had what you need: dialing
a number, receive a call, send and receive SMS messages, and have
addressbook for people you know (or you believe so). I admit some
features in newer phones are really useful: GPRS, different audio
themes for different people, etc. But, it’s getting to be
much more than “few new features”.
On the other
side, there are computers. They have a lot of features and a lot of
ways to brake things. We have viruses, adware, spyware… you
name it. Even without those (I’m using Linux, so I should know),
there are bugs in regular programs. Any thing that gives you power and
control must grow in complexity. Managing complexity is hard.
That’s one of the reasons the software has so many bugs.
The other is that programmers are often pushed to release new
versions without enough testing. Most software companies force
users to be beta testers. The companies that did testing on they
own and release software when it is really ready found their products
lose market share to competition that doesn’t do
that (IBM’s OS/2 comes to mind as a great example).
What
pulled me into writing this is that I own a Nokia 3660 phone. A very
good one. It has all the basic features you can find in Nokia phones,
plus GPRS, bluetooth and IR connectivity. On top of all that, is has
Symbian operating system. A new promising technology that will turn
our cell phones into computers. Why? Because market demands it. In
fact, I think that they couldn’t grow by selling cell phones
as they are. Something was needed to create a hype, so people would
buy new cell phone even if their old ones are fully
functional.
Symbian seemed like a great thing at first, and
I even liked and used some applications a lot. One of those is Agile
Messenger, for example (a very good multi-protocol IM client). Well,
only at first. After a year, I don’t think I was using any
Symbian application anymore. I was using it solely as a cell phone.
If I needed to browse the Internet, or read e-mail, my notebook was
always around, and I just used the GPRS+bluetooth combination to get to
the Web.
And recently, the problems started. I always hated that
I have to wait 70 seconds for my cell phone to turn on, but I understood
the reasons - it had an OS. Lately, it would pop some errors while
booting (Application closed - Etel. server). However, everything was
functioning properly. Until one day, it wouldn’t boot at all.
It would get to the main menu - show it for a second and then restarted.
I really don’t understand why? I had bluetooth turned off all the
time. Except sometime while GPRSing to the Internet, but that was
months before first signs of trouble begin.
People are
the service shop made a full reset, as there was no other way to
get it to work again. They said it might have been infected with
the virus. I don’t need to tell you that I lost the entire
address book and some other data as well (not that much important).
After all this, I’ll probably sell this “smart”
phone, and buy a “dumb” one. Perhaps I don’t
like machines being “smart” and doing stuff on their
own. Perhaps, that’s what “smart” stands for?
The “smart” machine would go it’s own way and
explore the unknown, without even telling you.
I past few weeks my colleagues at work and I have been testing resistance of our applications on the power failure. Most times we convince clients to have UPS with every computer which runs database server, but it cannot be done everywhere.
We are using default 3.6 ReiserFS supplied by Slackware 10.2. We powered off the machines by force - pulling out the plug. Some of the apps. did printing on printers, so even if filesystem would loose data, we would have printed log on the printer. The show begins: in about 20 power offs, we had lost parts of some files 3 times. Ok, perhaps that was expected, since filesystem data is kept in cache, and not committed each time write happens. Since we anticipated this, we weren’t much upset. The apps. are built in such way to be able to ignore this and keep working.
However, there are bugs in ReiserFS that do some really bad things. On one of the systems, a log file we were examinating (after power off) was missing a part at the end. Instead of not having anything, it had some garbage characters and parts of some other file! I guess we were “lucky” to have a textual file “inserted” so we noticed it. The file was a SiS graphic card include file (.h) which is (I think) part of kernel source, found in completely different part of the hard disk (same filesystem though). It wasn’t a whole file, just the part of it, approximately the same size as the missing part of log.
On the other system, we had a problem of some files in user’s home directory getting mysteriously corrupt. For example, file /home/omega/.ICEauthority got corrupted in such way that we can’t read, write, rename or delete it. We keep getting “permission denied” even when we set 777 permissions to both file and parent directory.
It is pretty absurd that they claim ReiserFS 3.6 stable, when such things can occur. I have seen systems that run Reiser for years, without troubles (notebook I’m writing this on for example), but to be honest, those had one or none forced power offs so far. One more interesting thing is that in all those problems, when we run reiserfsck (with various options), it wouldn’t detect the errors. It would just say that everything is ok.
I urge developers and system administrators not to use ReiserFS for important data (like databases for example). If there is any chance of power failures and you don’t have UPS, use some other filesystem. Which one? I don’t know. I made a list containing ext3, jfs and xfs. We’ll try those in the following weeks and see which one shows to be robust enough. Stay tuned…
Many times I get into argument why is Slackware distribution on my choice. I like it because it’s simple, robust and not bloated. But, I’m quite specific as I don’t try every app-of-the-day and only run what I really need. I can install and setup Slackware from scratch in few hours and start using it at full speed. How come? Well, take a look at the apps I’m running and you’ll see that I’m not that much of demanding user.
Well, I just tested BSCommander 2.20 today. Install was almost
too easy, as Slackware package is available from slacky.it. It has many
useful options I couldn’t find in other similar programs and idea
with tabs is excellent and done properly. It uses Qt library and works
really fast (which can’t be said for Krusader and Konqueror and
many others). Keyboard shortcuts are setup very good (although not
configurable).
Famous Backspace key works, which is great.
The file list flashes a little when navigating directories, but I can
live with that. File copying and similar ops work quite good and overall
visual look is pleasing. It really has potential to become the best tool
in this category, but some stuff needs to be fixed first, and some
features need to be added:
One thing I can’t find is
how to make the opposite panel display the same directory as the
current one (can be done with Meta+o in mc). Many times I just need
to move/copy some file few directories up or down the hierarchy, so
this one is crucial for me.
Another useful option that is
lacking is ability to open terminal in current directory (or at
least execute command there). Most other programs of this kind
have that feature. It would also be useful with FTP to be able
to send some command to the server (for example, when I connect
to ftp on Windows server, I need to type “cd d:” to
access second partition).
One of the things that could be fixed
is that it doesn’t remember the position (selected directory) during
FTP session. It works properly on local disk though.
Also, it is
not possible to copy directories via FTP, which doesn’t really make
FTP support useful.
To conclude, very cute program with lot of
potential. However, I’m still looking for decent GUI ftp client
for linux…
Well, I’ve seen a lot of those
Mozilla Quality Feedback Agent back on Windows 98. Since I switched completely to Linux in february this year, I haven’t had a single one. I even forgot it exists.
Now, look at that uglyness. It looks like it is not using Gtk, but rather like some TCL/Tk or even Xlib application. I hated the dialog on Windows - but this one is funny. It also ask about website I was visiting. Well, hard to remember as it was a Google search result, and the exact search term was … hm, can’t remember, but History will refresh my mind. Good thing history is saved before program exit.
Well, FF has to have it’s own BSOD, otherwise it wouldn’t be considered serious software.
If you take your browsers to this chess game, you might start to understand what I mean. This game has a great interface and is played against you by your own computer. Your moves do not get sent off to a server which comes up with a response and sends a move order back to your browser. The analisys of the play and the decision of the move is entierly done in Javascript, in your own machine, by the browser.
This is a really bad choice for web app. and their example only proves it.
After “check mate”-ing it in only 17 moves, the game started to consume 100% CPU. Luckily Mozilla figured out that it is better to shut it down (see screenshot).
My machine is AMD Turion(tm) 64 Mobile Technology MT-30 running at 1.6GHz. It has 512MB RAM, but only 1/2 of it is really used.
Let’s face it. AJAX is cool, but uses are limited. Being web-apps developer myself, I conclude that there are cases for AJAX, and there are cases when it shouldn’t be used. The smart developer isn’t one who knows how to implement it, but one who knows where and when to implement it.
Some time ago, all the projects I’m involved in, switched from CVS to Subversion. After I’ve seen how good it is, I switched all my projects as well (even the commercial stuff I’m working on). As I use Linux as my main OS, I started the quest to find a suitable graphical SVN client for Linux. I tried these:
1. KdeSVN 2. eSVN 3. RapidSVN
They all have a single problem in common. When you add a lot of files in your working copy, you should be able to painlessly add them to repository. TortoiseSVN (Subversion client from MS Windows) does it the proper way:
a) run “svn status”, and take all the files returned by it b) show that list with checkboxes so user can pick which of those unversioned files (s)he wants to add c) add them
Nice, simple and user-friendly. Unfortunately, none of those Linux programs have it. They all require that you pin-point each file. Sometimes I even add a file somewhere deep in directory structure, and forget about. I only catch the problem when I (or someone else) figure it is missing when working on another computer.
I tried to circumvent the problem by running the “status” command, but eSVN for example lists all files, since it envokes “svn status” with verbose flag. Who ever uses that feature I wonder?
Anyway, from all those, I prefer eSVN for its user interface. It is clean - so it’s easy to spot the changes, and it doesn’t flicker like RapidSVN. KDEsvn seems quite good, but it has a lot of background “syncing” with the repository (I think I’ve seen the option to turn it off, but didn’t bother). Why do tool makers add some extra-cool-whatever-used-by-nobody features instead of adding the esential ones? It really escapes me.
Given all this, I’m still using command-line svn from terminal most of the time. Sometimes I run svn status in terminal, and then hunt for files in GUI.
To all those “Linux desktop” proponents: If you want to see quality Linux desktop - make some pressure on developers of these tools (I’m trying by posting this on my blog).
All they need to implement is 4 basic svn commands:
svn update svn commit svn add svn status
And they need to do it properly. We can do checkout manually, we can do merging and other once-a-year stuff manually. But this day-to-day features must work. All the tools I tried only implemented update and commit as they should, “add” and “status” need to be connected.
Yeah, right. I just found some website that crashes Mozilla and Firefox few days ago. As I didn’t want to use Internet Explorer, I decided to give Opera a shot. So, I downloaded the latest version 8.53.
It works fine, but it’s far from being fastest. Most of the time it’s as good as any other, however on some pages with pictures shown in sizes smaller than original - it just sucks. Here are few pages that make Opera crawl:
One of the things I missed on Linux was a quality .chm file viewer. I installed xCHM about year (or more) ago. I was good, but missed important features like copy/paste and Index. Well, I just tried version 1.4, and I’m delighted.
Today I learned that there is also GnoCHM, but it requires Gnome which I don’t have installed on my Slackware, and it seems like overkill to install entire Gnome for this. Plus, many people have problems with available Gnome packages for Slackware, so I decided to forget about - especially after I tried new xCHM. It really rocks.
Some people might argue that it requires wxWidgets, but that’s not even a slight problem for me, as I develop wxWidgets based applications myself, so I already have it installed (in 5-6 different versions and configurations).
If you tried xCHM before and didn’t like it - give it another shot. There is no better way to read PHP manual (at least: known to me). CHM is superior to plain HTML documentation because it provides you with Index and Search features - and grep just isn’t that user friendly for this.
After seeing the screenshots with new graphics, I fetched the latest FreeCiv sources and tried it out. It’s great! Now, I see that 2.1 is getting close to release date, and I can hardly wait for it. FreeCiv is one of those rare games which have very high replayablity. I think I played it a 100 times already, if not much more.
New graphic, and some useful improvements like visual tech tree and stuff will probably get FreeCiv the status it deserves. When I tried to get some of my friends to play it before, they would comment that graphics is awful (although IMHO it wasn’t that bad), and they wouldn’t even try. I played the current development version with one of them, and she’s thrilled about that way everything looks and works now. I guess, all FreeCiv lacked before was some eye-candy.
Well, cheers for the best turn-based strategy game ever. (At least among open-sourced ones).
Just another annoying thing. I have setup up the KDE to do nothing when my laptop’s battery is about to run out, yet it logs me off no matter what. While I do appreciate it saving my filesystem (or whatever), most of the programs I use don’t get restored when I log back in (since they are not KDE apps.)
I just discovered
this very cool feature of Konsole. You can log into multiple
servers (via ssh) and run the same command in each Konsole tab
at once. It’s great when you have many computers with same
configuration. Just log in, and select one of Konsole’s tabs
to be the one to “broadcast” input to all others. It
works for all tabs in a single Konsole window.
It also
useful when you have several users on the same computer, and you
wish to make sure all of them have the same rights, and that they
can perform some operations without stepping on each others
toes.
One of the problems is monitoring the effects
of commands. Well, you can detach the tabs (Detach Session menu
item) after you set up the broadcasting. If you have large enough
screen, you can set up 8 or 9 windows nicely, and watch what’s
happening. Really useful stuff.
One warning though:
don’t forget to turn it off once you’re done. It’s
easy to forget yourself and start some clean-up
job (rm -rf /) which is
only meant to one of machines.
This
is one of the most annoying things I run into while using Linux (which
is 90% of the time I spend in front of computer).
When you open
a terminal (Konsole, for example) it gives you the default 80x24 size and
takes approx. 1/4 of your screen. Type in some long command, longer than a
single line. Run it. Ok, now press the UP arrow key to get it back.
Everything’s fine, the prompt scrolls up by a line, and you see the
command, just like you typed it.
Now, maximize the window. Try
doing the same. Sometimes, lines just get messed up. You don’t see
on the screen, what you’ve seen before - altough it is there. You
can edit, run, whetever. What’s worse, it doesn’t seem to
happen for some obvious reason - I tried to find the exact steps to
reproduce it, and failed. Still, it occurs on a daily basis, esp.
after I’ve been logged in on remote computer via ssh.
I’m
using ssh and scp on a daily basis, and here are some stuff I
dislike:
I use ssh most of the time to connect to one side of
some tunnel. Tunnels start at my localhost at different ports. So I use
something like:
ssh -p 22002 localhost ssh -p 22003 localhost etc.
However, I get: WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! …etc.
IMHO, ssh should use hostname+port instead of just hostname to identify hosts.
Next thing, scp and ssh don’t use the same flag to specify port.
Ssh uses -p, while scp uses -P. What’s even worse, if I sometimes
forget myself, and give -p to scp, it silently ignores it and tries to
contact the host at default port 22.
On our network, we also
have a dialup server. The client that connects to it, always gets the
same IP address (192.168.2.99). We use it when customer dials in,
just:
ssh 192.168.2.99
and we’re in… or not. Again, ssh’s protective mechanisms step in and alert - not just alert, but also
forbid the connection. In fact, that’s the main thing I
don’t like about it. Ok, give me a warning, give me an
option like:
Are you sure you wish to continue?
Instead of dreaded: Add correct host key in /home/milanb/.ssh/known_hosts to get rid of this message.
This is becoming really annoying.
I’m using KDE 3.4 (which comes with Slackware 10.2 - the
latest at the time of writing). AFAIK, Pat doesn’t alter
KDE sources, so this is definitely a problem in KDE.
I
happens almost every time: copy… and nothing gets into
clipboard. Even between KDE apps. It just happened between Kate and
Konsole. It’s even worse when you want to do Cut+Paste. Better
don’t close the app. until you pasted the text.
Yes, I
don’t run Klipper. Why should I? And guess what: doing copy the
second time works. So should I just do Copy twice each
time?
No, I’m not going to submit a bug report to KDE
team. If they don’t see this and aren’t annoyed, why
should I be, I’ll just switch back to IceWM or give Gnome
another shot.
This is the place where you can read my thoughts and opinions on
various stuff, but mostly software related stuff. I’ll rant about
what I dislike about some software products. I’m user and
programmer of Open Source software, so I’ll find the time
to criticize it, and also brag about bugs and things that annoy me.

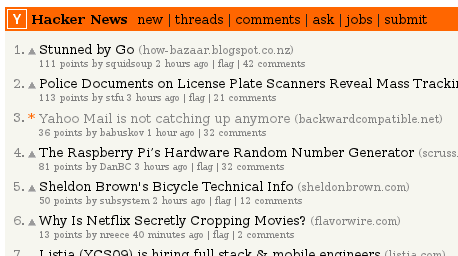
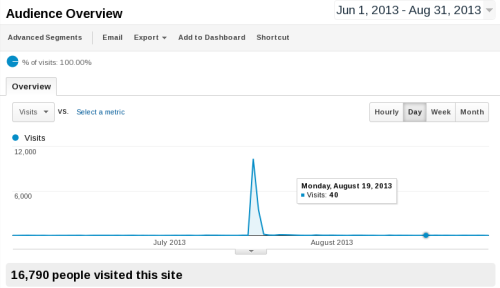


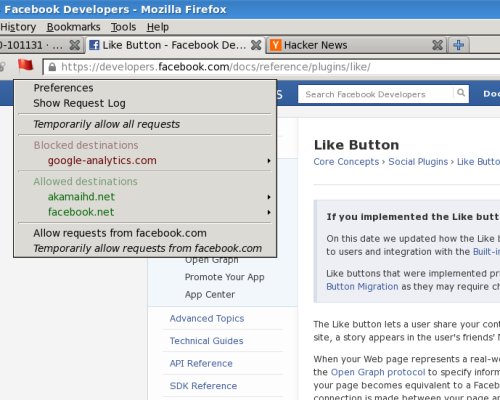





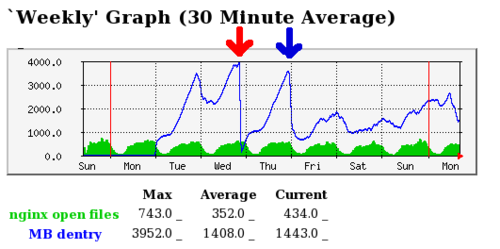
 I
just lost a couple hours on this. I’m making a puzzle game in HTML, so I used table to split an image into pieces and display each part at correct place. The problem is that I get weird space beneath every image, as part of TD tag. I tried everything, setting border, cellspacing, cellpadding to zero, playing with CSS margin, padding and display type. Nothing worked. And problem was visible in all browsers.
I
just lost a couple hours on this. I’m making a puzzle game in HTML, so I used table to split an image into pieces and display each part at correct place. The problem is that I get weird space beneath every image, as part of TD tag. I tried everything, setting border, cellspacing, cellpadding to zero, playing with CSS margin, padding and display type. Nothing worked. And problem was visible in all browsers.